TF-NumPy 类型提升#
| |
 在 Github 上查看源代码 在 Github 上查看源代码
|
|
文本特征向量#
TensorFlow 中的类型提升有 4 个选项。
默认情况下,TensorFlow 会引发错误,而不是提升混合类型运算的类型。
运行
tf.numpy.experimental_enable_numpy_behavior()会将 TensorFlow 切换为使用 NumPy 类型提升规则。本文档介绍了 TensorFlow 2.15(或目前为
tf-nightly)中提供的两个新选项:
from set_env import temp_dir
# !pip install -q tf_nightly
注:experimental_enable_numpy_behavior 会更改所有 TensorFlow 的行为。
安装#
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.17.0
启用新类型提升#
为了在 TF-Numpy 中使用类似 JAX 的类型提升,请在为 TensorFlow 启用 NumPy 行为时指定 'all' 或 'safe' 作为数据类型转换模式。
此新系统 (dtype_conversion_mode="all") 可结合、可交换,并且可以轻松控制最终的浮点数宽度(它不会自动转换为更宽的浮点数)。它确实引入了一些溢出和精度损失的风险,但 dtype_conversion_mode="safe" 会强制您显式处理这些情况。下一部分将更详细地解释这两种模式。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
两种模式:ALL 模式与 SAFE 模式#
在新提升系统中,我们引入了两种模式:ALL 模式和 SAFE 模式。SAFE 模式用于减轻可能导致精度损失或位加宽的“风险”提升的担忧。
数据类型#
为简洁起见,我们将使用以下缩写。
b表示tf.boolu8表示tf.uint8i16表示tf.int16i32表示tf.int32bf16表示tf.bfloat16f32表示tf.float32f64表示tf.float64i32*表示 Pythonint或弱类型i32f32*表示 Pythonfloat浮点型或弱类型f32c128*表示 Pythoncomplex或弱类型c128
星号 (*) 表示相应的类型是“弱类型”- 此类数据类型是由系统临时推断的,可以遵从其他数据类型。此处更详细地解释了这个概念。
精度损失运算示例#
在以下示例中,ALL 模式下允许使用 i32 + f32,但由于精度损失的风险,SAFE 模式下不允许使用。
# i32 + f32 returns a f32 result in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, dtype = tf.int32)
b = tf.constant(5.0, dtype = tf.float32)
a + b # <tf.Tensor: shape=(), dtype=float32, numpy=15.0>
<tf.Tensor: shape=(), dtype=float32, numpy=15.0>
# This promotion is not allowed in SAFE mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="safe")
a = tf.constant(10, dtype = tf.int32)
b = tf.constant(5.0, dtype = tf.float32)
try:
a + b
except TypeError as e:
print(f'{type(e)}: {e}') # TypeError: explicitly specify the dtype or switch to ALL mode.
<class 'TypeError'>: In promotion mode PromoMode.SAFE, implicit dtype promotion between (<dtype: 'int32'>, weak=False) and (<dtype: 'float32'>, weak=False) is disallowed. You need to explicitly specify the dtype in your op, or relax your dtype promotion rules (such as from SAFE mode to ALL mode).
位加宽运算示例#
在以下示例中,ALL 模式下允许使用 i8 + u32,但由于位加宽,SAFE 模式下不允许使用,这意味着使用的位数多于输入中的位数。请注意,新的类型提升语义仅允许必要的位加宽。
# i8 + u32 returns an i64 result in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, dtype = tf.int8)
b = tf.constant(5, dtype = tf.uint32)
a + b
<tf.Tensor: shape=(), dtype=int64, numpy=15>
# This promotion is not allowed in SAFE mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="safe")
a = tf.constant(10, dtype = tf.int8)
b = tf.constant(5, dtype = tf.uint32)
try:
a + b
except TypeError as e:
print(f'{type(e)}: {e}') # TypeError: explicitly specify the dtype or switch to ALL mode.
<class 'TypeError'>: In promotion mode PromoMode.SAFE, implicit dtype promotion between (<dtype: 'int8'>, weak=False) and (<dtype: 'uint32'>, weak=False) is disallowed. You need to explicitly specify the dtype in your op, or relax your dtype promotion rules (such as from SAFE mode to ALL mode).
基于点阵的系统#
类型提升点阵#
新的类型提升行为通过以下类型提升点阵来确定:
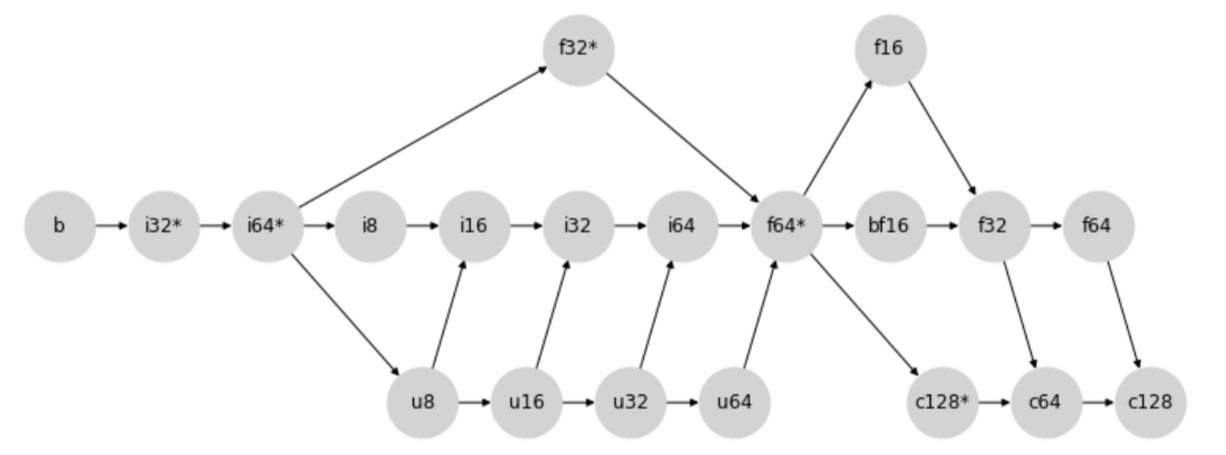
更具体地说,任何两种类型之间的提升是通过查找两个节点的第一个公共子节点(包括节点本身)来确定的。
例如,在上图中,i8 和 i32 的第一个公共子节点是 i32,因为沿着箭头方向,这两个节点在 i32 处第一次相交。
类似地,在另一个示例中,u64 和 f16 之间的结果提升类型为 f16。
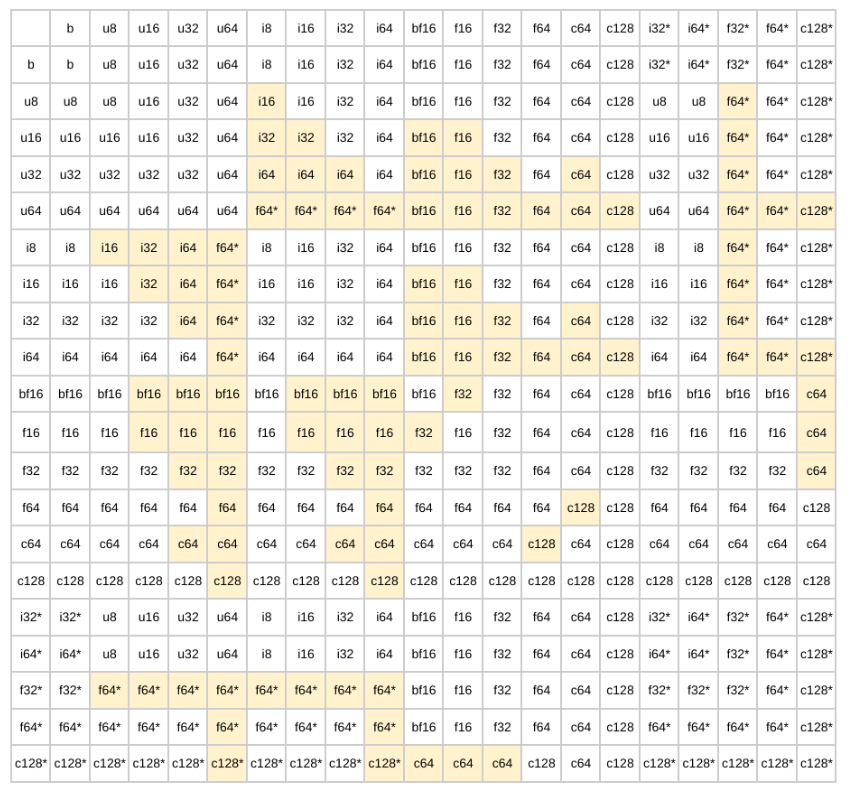
类型提升表#
按照点阵行进会生成下面的二进制提升表:
注:SAFE 不允许高亮显示的单元格。ALL 模式允许全部情况。
新类型提升的优点#
我们针对新类型提升采用类似 JAX 的基于点阵的系统,它具有以下优点:
基于点阵的系统的优点#
首先,使用基于点阵的系统可以确保三个非常重要的属性:
存在性:任何类型的组合都存在唯一的结果提升类型。
交换性:
a + b = b + a结合性:
a + (b + c) = (a + b) = c
这三个属性对于构建一致且可预测的类型提升语义至关重要。
类似 JAX 的点阵系统的优点#
类似 JAX 的点阵系统的另一个重要优点是,除了无符号整数之外,它避免了所有超出必要范围的提升。这意味着没有 64 位输入就无法获得 64 位结果。这对于加速器上的工作特别有利,因为它可以避免不必要的 64 位值,这在旧类型提升中十分常见。
不过,这需要一定的权衡:混合浮点/整数提升很容易导致精度损失。例如,在下面的示例中,i64 + f16 会导致将 i64 提升为 f16。
# The first input is promoted to f16 in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
tf.constant(1, tf.int64) + tf.constant(3.2, tf.float16) # <tf.Tensor: shape=(), dtype=float16, numpy=4.2>
<tf.Tensor: shape=(), dtype=float16, numpy=4.2>
为了缓解这种担忧,我们引入了 SAFE 模式,此模式会禁止这些“风险”提升。
注:要详细了解构造点阵系统的设计注意事项,请参阅 JAX 的类型提升语义设计。
WeakTensor#
概述#
WeakTensor 是“弱类型”的张量,类似于 JAX 中的概念。
WeakTensor 的数据类型是由系统临时推断的,并且可以遵从其他数据类型。在新类型提升中引入此概念的目的是防止 TF 值与没有用户显式指定类型的值(例如 Python 标量文字)之间的二进制运算中出现不需要的类型提升。
例如,在下面的示例中,tf.constant(1.2) 被视为“弱”,因为它没有特定的数据类型。因此,tf.constant(1.2) 遵从 tf.constant(3.1, tf.float16) 的类型,产生 f16 输出。
tf.constant(1.2) + tf.constant(3.1, tf.float16) # <tf.Tensor: shape=(), dtype=float16, numpy=4.3>
<tf.Tensor: shape=(), dtype=float16, numpy=4.3>
WeakTensor 构造#
如果您创建张量而不指定数据类型,则会创建 WeakTensor。可以通过检查张量字符串表示末尾的弱特性来检查张量是否为“弱”张量。
第一种情况:使用没有用户指定数据类型的输入调用 tf.constant 时。
tf.constant(5) # <tf.Tensor: shape=(), dtype=int32, numpy=5, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=5, weak=True>
tf.constant([5.0, 10.0, 3]) # <tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 5., 10., 3.], dtype=float32), weak=True>
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 5., 10., 3.], dtype=float32), weak=True>
# A normal Tensor is created when dtype arg is specified.
tf.constant(5, tf.int32) # <tf.Tensor: shape=(), dtype=int32, numpy=5>
<tf.Tensor: shape=(), dtype=int32, numpy=5>
第二种情况:当没有用户指定数据类型的输入被传递到支持 WeakTensor 的 API 中时。
tf.math.abs([100.0, 4.0]) # <tf.Tensor: shape=(2,), dtype=float32, numpy=array([100., 4.], dtype=float32), weak=True>
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([100., 4.], dtype=float32), weak=True>
##开启新类型提升的效果
以下是由于开启新类型提升而引起的更改的非详尽清单。
提升结果更一致且可预测。
降低位加宽的风险。
tf.Tensor数学 dunder 方法使用新类型提升。tf.constant可以返回WeakTensor。当传入一个数据类型与
dtype参数不同的张量输入时,tf.constant允许隐式转换。tf.Variable就地运算(assign、assign-add、assign-sub)允许隐式转换。tnp.array(1)和tnp.array(1.0)返回 32 位 WeakTensor。将创建
WeakTensor用于支持 WeakTensor 的一元和二元 API。
提升结果更一致且可预测性提升#
使用基于点阵的系统允许新类型提升产生一致且可预测的类型提升结果。
旧类型提升#
使用旧类型提升更改运算顺序会产生不一致的结果。
# Setup
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="legacy")
a = np.array(1, dtype=np.int8)
b = tf.constant(1)
c = np.array(1, dtype=np.float16)
# (a + b) + c throws an InvalidArgumentError.
try:
tf.add(tf.add(a, b), c)
except tf.errors.InvalidArgumentError as e:
print(f'{type(e)}: {e}') # InvalidArgumentError
<class 'tensorflow.python.framework.errors_impl.InvalidArgumentError'>: cannot compute AddV2 as input #1(zero-based) was expected to be a int8 tensor but is a int32 tensor [Op:AddV2] name:
# (b + a) + c returns an i32 result.
tf.add(tf.add(b, a), c) # <tf.Tensor: shape=(), dtype=int32, numpy=3>
<tf.Tensor: shape=(), dtype=int32, numpy=3>
新类型提升#
无论顺序如何,新类型提升都会产生一致的结果。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = np.array(1, dtype=np.int8)
b = tf.constant(1)
c = np.array(1, dtype=np.float16)
# (a + b) + c returns a f16 result.
tf.add(tf.add(a, b), c) # <tf.Tensor: shape=(), dtype=float16, numpy=3.0>
<tf.Tensor: shape=(), dtype=float16, numpy=3.0>
# (b + a) + c also returns a f16 result.
tf.add(tf.add(b, a), c) # <tf.Tensor: shape=(), dtype=float16, numpy=3.0>
<tf.Tensor: shape=(), dtype=float16, numpy=3.0>
降低位加宽的风险#
旧类型提升#
旧类型提升通常会产生 64 位结果。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="legacy")
np.array(3.2, np.float16) + tf.constant(1, tf.int8) + tf.constant(50) # <tf.Tensor: shape=(), dtype=float64, numpy=54.19921875>
<tf.Tensor: shape=(), dtype=float64, numpy=54.19921875>
新类型提升#
新类型提升返回所需位数最少的结果。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
np.array(3.2, np.float16) + tf.constant(1, tf.int8) + tf.constant(50) # <tf.Tensor: shape=(), dtype=float16, numpy=54.2>
<tf.Tensor: shape=(), dtype=float16, numpy=54.2>
tf.Tensor 数学 dunder 方法#
所有 tf.Tensor 数学 dunder 方法都将遵循新类型提升。
-tf.constant(5) # <tf.Tensor: shape=(), dtype=int32, numpy=-5, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=-5, weak=True>
tf.constant(5, tf.int16) - tf.constant(1, tf.float32) # <tf.Tensor: shape=(), dtype=float32, numpy=4.0>
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
tf.Variable 就地运算#
tf.Variable 就地运算中允许隐式转换。
注:任何导致数据类型与变量的原始数据类型不同的提升都是不允许的。原因是 tf.Variable 不能更改其数据类型。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.Variable(10, tf.int32)
a.assign_add(tf.constant(5, tf.int16)) # <tf.Variable shape=() dtype=int32, numpy=15>
<tf.Variable 'UnreadVariable' shape=() dtype=int32, numpy=15>
tf.constant 隐式转换#
在旧类型提升中,tf.constant 要求输入张量与数据类型参数具有相同的数据类型。不过,在新类型提升中,我们将张量隐式转换为指定的数据类型。
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, tf.int16)
tf.constant(a, tf.float32) # <tf.Tensor: shape=(), dtype=float32, numpy=10.0>
<tf.Tensor: shape=(), dtype=float32, numpy=10.0>
TF-NumPy 数组#
对于使用新类型提升的 Python 输入,tnp.array 默认为 i32* 和 f32*。
tnp.array(1) # <tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
tnp.array(1.0) # <tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
<tf.Tensor: shape=(), dtype=float32, numpy=1.0, weak=True>
##输入类型推断
下面是在新类型提升中推断不同输入类型的方式。
tf.Tensor:由于tf.Tensor具有数据类型属性,我们不做进一步的推断。NumPy 类型:包括
np.array(1)、np.int16(1)和np.float等类型。由于 NumPy 输入也具有数据类型属性,我们将数据类型属性作为结果推断类型。请注意,NumPy 默认为i64和f64。Python 标量/嵌套类型:包括
1、[1, 2, 3]和(1.0, 2.0)等类型。Python
int被推断为i32*。Python
float被推断为f32*。Python
complex被推断为c128*。
如果输入不属于上述任何类别,但具有数据类型属性,我们将数据类型属性作为结果推断类型。
延伸阅读#
新类型提升与 JAX-NumPy 的类型提升非常相似。如果想了解有关新类型提升和设计选择的更多详细信息,请查阅以下资源。
参考#
支持 WeakTensor 的 API#
以下是支持 WeakTensor 的 API 列表。
对于一元运算,这意味着如果传入没有用户指定类型的输入,它将返回 WeakTensor。
对于二元运算,它将遵循此处的提升表。它可能会也可能不会返回 WeakTensor,具体取决于两个输入的提升结果。
注:支持所有数学运算(+、-、*、…)。
tf.bitwise.inverttf.clip_by_valuetf.debugging.check_numericstf.expand_dimstf.identitytf.image.adjust_brightnesstf.image.adjust_gammatf.image.extract_patchestf.image.random_brightnesstf.image.stateless_random_brightnesstf.linalg.diagtf.linalg.diag_parttf.linalg.matmultf.linalg.matrix_transposetf.linalg.tensor_diag_parttf.linalg.tracetf.math.abstf.math.acostf.math.acoshtf.math.addtf.math.angletf.math.asintf.math.asinhtf.math.atantf.math.atanhtf.math.ceiltf.math.conjtf.math.costf.math.coshtf.math.digammatf.math.divide_no_nantf.math.dividetf.math.erftf.math.erfctf.math.erfcinvtf.math.erfinvtf.math.exptf.math.expm1tf.math.floortf.math.floordivtf.math.floormodtf.math.imagtf.math.lgammatf.math.log1ptf.math.log_sigmoidtf.math.logtf.math.multiply_no_nantf.math.multiplytf.math.ndtritf.math.negativetf.math.powtf.math.realtf.math.realtf.math.reciprocal_no_nantf.math.reciprocaltf.math.reduce_euclidean_normtf.math.reduce_logsumexptf.math.reduce_maxtf.math.reduce_meantf.math.reduce_mintf.math.reduce_prodtf.math.reduce_stdtf.math.reduce_sumtf.math.reduce_variancetf.math.rinttf.math.roundtf.math.rsqrttf.math.scalar_multf.math.sigmoidtf.math.signtf.math.sintf.math.sinhtf.math.softplustf.math.special.bessel_i0tf.math.special.bessel_i0etf.math.special.bessel_i1tf.math.special.bessel_i1etf.math.special.bessel_j0tf.math.special.bessel_j1tf.math.special.bessel_k0tf.math.special.bessel_k0etf.math.special.bessel_k1tf.math.special.bessel_k1etf.math.special.bessel_y0tf.math.special.bessel_y1tf.math.special.dawsntf.math.special.expinttf.math.special.fresnel_costf.math.special.fresnel_sintf.math.special.spencetf.math.sqrttf.math.squaretf.math.subtracttf.math.tantf.math.tanhtf.nn.depth_to_spacetf.nn.elutf.nn.gelutf.nn.leaky_relutf.nn.log_softmaxtf.nn.relu6tf.nn.relutf.nn.selutf.nn.softsigntf.nn.space_to_depthtf.nn.swishtf.ones_liketf.realdivtf.reshapetf.squeezetf.stop_gradienttf.transposetf.truncatedivtf.truncatemodtf.zeros_liketf.experimental.numpy.abstf.experimental.numpy.absolutetf.experimental.numpy.amaxtf.experimental.numpy.amintf.experimental.numpy.angletf.experimental.numpy.arangetf.experimental.numpy.arccostf.experimental.numpy.arccoshtf.experimental.numpy.arcsintf.experimental.numpy.arcsinhtf.experimental.numpy.arctantf.experimental.numpy.arctanhtf.experimental.numpy.aroundtf.experimental.numpy.arraytf.experimental.numpy.asanyarraytf.experimental.numpy.asarraytf.experimental.numpy.ascontiguousarraytf.experimental.numpy.averagetf.experimental.numpy.bitwise_nottf.experimental.numpy.cbrttf.experimental.numpy.ceiltf.experimental.numpy.conjtf.experimental.numpy.conjugatetf.experimental.numpy.copytf.experimental.numpy.costf.experimental.numpy.coshtf.experimental.numpy.cumprodtf.experimental.numpy.cumsumtf.experimental.numpy.deg2radtf.experimental.numpy.diagtf.experimental.numpy.diagflattf.experimental.numpy.diagonaltf.experimental.numpy.difftf.experimental.numpy.empty_liketf.experimental.numpy.exp2tf.experimental.numpy.exptf.experimental.numpy.expand_dimstf.experimental.numpy.expm1tf.experimental.numpy.fabstf.experimental.numpy.fixtf.experimental.numpy.flattentf.experimental.numpy.fliptf.experimental.numpy.fliplrtf.experimental.numpy.flipudtf.experimental.numpy.floortf.experimental.numpy.full_liketf.experimental.numpy.imagtf.experimental.numpy.log10tf.experimental.numpy.log1ptf.experimental.numpy.log2tf.experimental.numpy.logtf.experimental.numpy.maxtf.experimental.numpy.meantf.experimental.numpy.mintf.experimental.numpy.moveaxistf.experimental.numpy.nanmeantf.experimental.numpy.negativetf.experimental.numpy.ones_liketf.experimental.numpy.positivetf.experimental.numpy.prodtf.experimental.numpy.rad2degtf.experimental.numpy.raveltf.experimental.numpy.realtf.experimental.numpy.reciprocaltf.experimental.numpy.repeattf.experimental.numpy.reshapetf.experimental.numpy.rot90tf.experimental.numpy.roundtf.experimental.numpy.signbittf.experimental.numpy.sintf.experimental.numpy.sinctf.experimental.numpy.sinhtf.experimental.numpy.sorttf.experimental.numpy.sqrttf.experimental.numpy.squaretf.experimental.numpy.squeezetf.experimental.numpy.stdtf.experimental.numpy.sumtf.experimental.numpy.swapaxestf.experimental.numpy.tantf.experimental.numpy.tanhtf.experimental.numpy.tracetf.experimental.numpy.transposetf.experimental.numpy.triutf.experimental.numpy.vandertf.experimental.numpy.vartf.experimental.numpy.zeros_like