##### Copyright 2022 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
| |
|
 在 Github 上查看源代码 在 Github 上查看源代码 |
|
使用 MoViNet 进行视频分类的迁移学习#
MoViNets(移动视频网络)提供了一系列高效的视频分类模型,支持对流式视频进行推断。在本教程中,您将使用预训练的 MoViNet 模型对来自 UCF101 数据集的视频进行分类,特别是针对动作识别任务。预训练模型是一个先前在更大数据集上训练过的已保存网络。可以在 Kondratyuk, D. 等人 2021 年撰写的 MoViNets: Mobile Video Networks for Efficient Video Recognition 论文中找到有关 MoViNets 的更多详细信息。在本教程中,您将完成以下任务:
了解如何下载预训练的 MoViNet 模型
通过冻结 MoViNet 模型的卷积基,使用带有新分类器的预训练模型创建新模型
将分类器头替换为新数据集的标签数
在 UCF101 数据集上执行迁移学习
本教程下载的模型来自 official/projects/movinet。此仓库包含 TF Hub 在 TensorFlow 2 SavedModel 格式中使用的 MoViNet 模型集合。
本视频加载和预处理教程是 TensorFlow 视频教程系列的第一部分。下面是其他三个教程:
加载视频数据:本教程解释了本文档中使用的大部分代码;特别是,更详细地解释了如何通过
FrameGenerator类预处理和加载数据。构建用于视频分类的 3D CNN 模型。请注意,本教程使用分解 3D 数据的空间和时间方面的 (2+1)D CNN;如果使用 MRI 扫描等体数据,请考虑使用 3D CNN 而不是 (2+1)D CNN。
用于流式动作识别的 MoViNet:熟悉 TF Hub 上提供的 MoViNet 模型。
安装#
首先,安装并导入一些必要的库,包括:用于检查 ZIP 文件内容的 remotezip,用于使用进度条的 tqdm,用于处理视频文件的 OpenCV(确保 opencv-python 和 opencv-python-headless 是同一版本),以及用于下载预训练 MoViNet 模型的 TensorFlow 模型 (tf-models- official)。TensorFlow 模型软件包是一组使用 TensorFlow 高级 API 的模型。
!pip install remotezip tqdm opencv-python==4.5.2.52 opencv-python-headless==4.5.2.52 tf-models-official
import tqdm
import random
import pathlib
import itertools
import collections
import cv2
import numpy as np
import remotezip as rz
import seaborn as sns
import matplotlib.pyplot as plt
import keras
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
# Import the MoViNet model from TensorFlow Models (tf-models-official) for the MoViNet model
from official.projects.movinet.modeling import movinet
from official.projects.movinet.modeling import movinet_model
加载数据#
下面的隐藏单元定义了从 UCF-101 数据集下载数据切片并将其加载到 tf.data.Dataset 中的函数。加载视频数据教程详细地介绍了此代码。
隐藏块末尾的 FrameGenerator 类是这里最重要的实用工具。它会创建一个可以将数据馈送到 TensorFlow 数据流水线中的可迭代对象。具体来说,此类包含一个可加载视频帧及其编码标签的 Python 生成器。生成器 (__call__) 函数可产生由 frames_from_video_file 生成的帧数组以及与帧集关联的标签的独热编码向量。
#@title
def list_files_per_class(zip_url):
"""
List the files in each class of the dataset given the zip URL.
Args:
zip_url: URL from which the files can be unzipped.
Return:
files: List of files in each of the classes.
"""
files = []
with rz.RemoteZip(URL) as zip:
for zip_info in zip.infolist():
files.append(zip_info.filename)
return files
def get_class(fname):
"""
Retrieve the name of the class given a filename.
Args:
fname: Name of the file in the UCF101 dataset.
Return:
Class that the file belongs to.
"""
return fname.split('_')[-3]
def get_files_per_class(files):
"""
Retrieve the files that belong to each class.
Args:
files: List of files in the dataset.
Return:
Dictionary of class names (key) and files (values).
"""
files_for_class = collections.defaultdict(list)
for fname in files:
class_name = get_class(fname)
files_for_class[class_name].append(fname)
return files_for_class
def download_from_zip(zip_url, to_dir, file_names):
"""
Download the contents of the zip file from the zip URL.
Args:
zip_url: Zip URL containing data.
to_dir: Directory to download data to.
file_names: Names of files to download.
"""
with rz.RemoteZip(zip_url) as zip:
for fn in tqdm.tqdm(file_names):
class_name = get_class(fn)
zip.extract(fn, str(to_dir / class_name))
unzipped_file = to_dir / class_name / fn
fn = pathlib.Path(fn).parts[-1]
output_file = to_dir / class_name / fn
unzipped_file.rename(output_file,)
def split_class_lists(files_for_class, count):
"""
Returns the list of files belonging to a subset of data as well as the remainder of
files that need to be downloaded.
Args:
files_for_class: Files belonging to a particular class of data.
count: Number of files to download.
Return:
split_files: Files belonging to the subset of data.
remainder: Dictionary of the remainder of files that need to be downloaded.
"""
split_files = []
remainder = {}
for cls in files_for_class:
split_files.extend(files_for_class[cls][:count])
remainder[cls] = files_for_class[cls][count:]
return split_files, remainder
def download_ufc_101_subset(zip_url, num_classes, splits, download_dir):
"""
Download a subset of the UFC101 dataset and split them into various parts, such as
training, validation, and test.
Args:
zip_url: Zip URL containing data.
num_classes: Number of labels.
splits: Dictionary specifying the training, validation, test, etc. (key) division of data
(value is number of files per split).
download_dir: Directory to download data to.
Return:
dir: Posix path of the resulting directories containing the splits of data.
"""
files = list_files_per_class(zip_url)
for f in files:
tokens = f.split('/')
if len(tokens) <= 2:
files.remove(f) # Remove that item from the list if it does not have a filename
files_for_class = get_files_per_class(files)
classes = list(files_for_class.keys())[:num_classes]
for cls in classes:
new_files_for_class = files_for_class[cls]
random.shuffle(new_files_for_class)
files_for_class[cls] = new_files_for_class
# Only use the number of classes you want in the dictionary
files_for_class = {x: files_for_class[x] for x in list(files_for_class)[:num_classes]}
dirs = {}
for split_name, split_count in splits.items():
print(split_name, ":")
split_dir = download_dir / split_name
split_files, files_for_class = split_class_lists(files_for_class, split_count)
download_from_zip(zip_url, split_dir, split_files)
dirs[split_name] = split_dir
return dirs
def format_frames(frame, output_size):
"""
Pad and resize an image from a video.
Args:
frame: Image that needs to resized and padded.
output_size: Pixel size of the output frame image.
Return:
Formatted frame with padding of specified output size.
"""
frame = tf.image.convert_image_dtype(frame, tf.float32)
frame = tf.image.resize_with_pad(frame, *output_size)
return frame
def frames_from_video_file(video_path, n_frames, output_size = (224,224), frame_step = 15):
"""
Creates frames from each video file present for each category.
Args:
video_path: File path to the video.
n_frames: Number of frames to be created per video file.
output_size: Pixel size of the output frame image.
Return:
An NumPy array of frames in the shape of (n_frames, height, width, channels).
"""
# Read each video frame by frame
result = []
src = cv2.VideoCapture(str(video_path))
video_length = src.get(cv2.CAP_PROP_FRAME_COUNT)
need_length = 1 + (n_frames - 1) * frame_step
if need_length > video_length:
start = 0
else:
max_start = video_length - need_length
start = random.randint(0, max_start + 1)
src.set(cv2.CAP_PROP_POS_FRAMES, start)
# ret is a boolean indicating whether read was successful, frame is the image itself
ret, frame = src.read()
result.append(format_frames(frame, output_size))
for _ in range(n_frames - 1):
for _ in range(frame_step):
ret, frame = src.read()
if ret:
frame = format_frames(frame, output_size)
result.append(frame)
else:
result.append(np.zeros_like(result[0]))
src.release()
result = np.array(result)[..., [2, 1, 0]]
return result
class FrameGenerator:
def __init__(self, path, n_frames, training = False):
""" Returns a set of frames with their associated label.
Args:
path: Video file paths.
n_frames: Number of frames.
training: Boolean to determine if training dataset is being created.
"""
self.path = path
self.n_frames = n_frames
self.training = training
self.class_names = sorted(set(p.name for p in self.path.iterdir() if p.is_dir()))
self.class_ids_for_name = dict((name, idx) for idx, name in enumerate(self.class_names))
def get_files_and_class_names(self):
video_paths = list(self.path.glob('*/*.avi'))
classes = [p.parent.name for p in video_paths]
return video_paths, classes
def __call__(self):
video_paths, classes = self.get_files_and_class_names()
pairs = list(zip(video_paths, classes))
if self.training:
random.shuffle(pairs)
for path, name in pairs:
video_frames = frames_from_video_file(path, self.n_frames)
label = self.class_ids_for_name[name] # Encode labels
yield video_frames, label
URL = 'https://storage.googleapis.com/thumos14_files/UCF101_videos.zip'
download_dir = pathlib.Path('./UCF101_subset/')
subset_paths = download_ufc_101_subset(URL,
num_classes = 10,
splits = {"train": 30, "test": 20},
download_dir = download_dir)
创建训练并测试数据集:
batch_size = 8
num_frames = 8
output_signature = (tf.TensorSpec(shape = (None, None, None, 3), dtype = tf.float32),
tf.TensorSpec(shape = (), dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'], num_frames, training = True),
output_signature = output_signature)
train_ds = train_ds.batch(batch_size)
test_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['test'], num_frames),
output_signature = output_signature)
test_ds = test_ds.batch(batch_size)
此处生成的标签表示类的编码。例如,“ApplyEyeMakeup”被映射到整数。查看训练数据的标签,确保数据集已被充分重排。
for frames, labels in train_ds.take(10):
print(labels)
查看数据的形状。
print(f"Shape: {frames.shape}")
print(f"Label: {labels.shape}")
什么是 MoViNets?#
如前所述,MoViNets 是用于流式传输视频或动作识别等任务中的在线推断的视频分类模型。考虑使用 MoViNets 对您的视频数据进行分类以进行动作识别。
基于 2D 帧的分类器高效且可简单地运行整个视频,或者一次流式传输一帧。由于它们不能考虑时间上下文,它们的准确率有限,并且可能会在帧与帧之间给出不一致的输出。
一个简单的 3D CNN 使用双向时间上下文,可以提高准确率和时间一致性。这些网络可能需要更多资源,并且由于它们着眼于未来,不能用于流式传输数据。
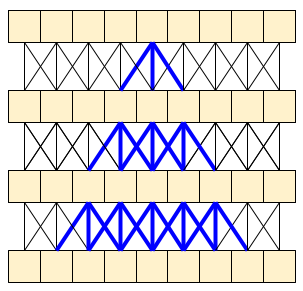
MoViNet 架构使用沿时间轴“因果”的 3D 卷积(如 padding="causal" 的 layers.Conv1D)。这提供了两种方式的一些优点,主要是它允许高效流式传输。
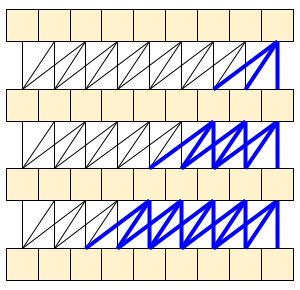
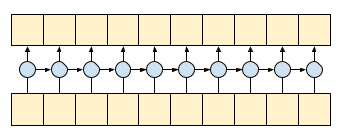
因果卷积确保仅使用直到时间 t 的输入来计算时间 t 的输出。为了演示这如何提高流式传输的效率,请从您可能熟悉的一个更简单示例开始:RNN。RNN 通过时间向前传递状态:
gru = layers.GRU(units=4, return_sequences=True, return_state=True)
inputs = tf.random.normal(shape=[1, 10, 8]) # (batch, sequence, channels)
result, state = gru(inputs) # Run it all at once
通过设置 RNN 的 return_sequences=True 参数,可以要求它在计算结束时返回状态。这样,您就可以暂停,随后从上次中断的地方继续,以获得完全相同的结果:
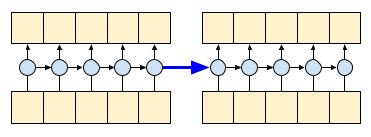
first_half, state = gru(inputs[:, :5, :]) # run the first half, and capture the state
second_half, _ = gru(inputs[:,5:, :], initial_state=state) # Use the state to continue where you left off.
print(np.allclose(result[:, :5,:], first_half))
print(np.allclose(result[:, 5:,:], second_half))
如果小心处理,因果卷积能以相同的方式使用。Le Paine 等人在 Fast Wavenet Generation Algorithm 中使用了这种技术。在 MoVinet 论文中,state 被称为“流缓冲区”。
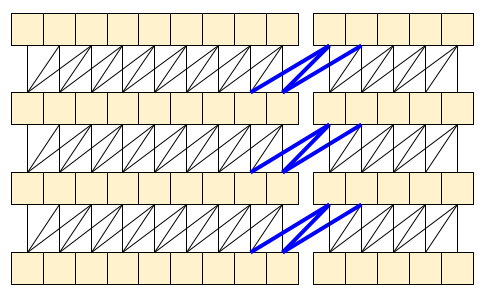
通过向前传递这一点状态,可以避免重新计算上面显示的整个感受域。
下载预训练的 MoViNet 模型#
在本部分中,您将:
可以使用 TensorFlow 模型的
official/projects/movinet中提供的开源代码创建 MoViNet 模型。加载预训练的权重。
冻结卷积基或除最终分类器头之外的所有其他层,以加快微调速度。
要构建模型,您可以从 a0 配置开始,因为在针对其他模型进行基准分析时,它的训练速度最快。查看 TensorFlow Model Garden 上的可用 MoViNet 模型,了解哪些模型可能适用于您的用例。
model_id = 'a0'
resolution = 224
tf.keras.backend.clear_session()
backbone = movinet.Movinet(model_id=model_id)
backbone.trainable = False
# Set num_classes=600 to load the pre-trained weights from the original model
model = movinet_model.MovinetClassifier(backbone=backbone, num_classes=600)
model.build([None, None, None, None, 3])
# Load pre-trained weights
!wget https://storage.googleapis.com/tf_model_garden/vision/movinet/movinet_a0_base.tar.gz -O movinet_a0_base.tar.gz -q
!tar -xvf movinet_a0_base.tar.gz
checkpoint_dir = f'movinet_{model_id}_base'
checkpoint_path = tf.train.latest_checkpoint(checkpoint_dir)
checkpoint = tf.train.Checkpoint(model=model)
status = checkpoint.restore(checkpoint_path)
status.assert_existing_objects_matched()
要构建分类器,请创建一个采用主干和数据集中的类数的函数。build_classifier 函数将采用主干和数据集中的类数来构建分类器。在这种情况下,新分类器将采用 num_classes 个输出(UCF101 的此子集有 10 个类)。
def build_classifier(batch_size, num_frames, resolution, backbone, num_classes):
"""Builds a classifier on top of a backbone model."""
model = movinet_model.MovinetClassifier(
backbone=backbone,
num_classes=num_classes)
model.build([batch_size, num_frames, resolution, resolution, 3])
return model
model = build_classifier(batch_size, num_frames, resolution, backbone, 10)
对于本教程,选择 tf.keras.optimizers.Adam 优化器和 tf.keras.losses.SparseCategoricalCrossentropy 损失函数。使用指标参数查看每个步骤中模型性能的准确率。
num_epochs = 2
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001)
model.compile(loss=loss_obj, optimizer=optimizer, metrics=['accuracy'])
训练模型。两个周期后,观察训练集和测试集的低损失和高准确率。
results = model.fit(train_ds,
validation_data=test_ds,
epochs=num_epochs,
validation_freq=1,
verbose=1)
评估模型#
该模型在训练数据集上取得了很高的准确率。接下来,使用 Keras Model.evaluate 在测试集上对其进行评估。
model.evaluate(test_ds, return_dict=True)
要进一步呈现模型性能,请使用混淆矩阵。混淆矩阵允许评估分类模型的性能,而不仅仅是准确率。为了构建此多类分类问题的混淆矩阵,需要获得测试集中的实际值和预测值。
def get_actual_predicted_labels(dataset):
"""
Create a list of actual ground truth values and the predictions from the model.
Args:
dataset: An iterable data structure, such as a TensorFlow Dataset, with features and labels.
Return:
Ground truth and predicted values for a particular dataset.
"""
actual = [labels for _, labels in dataset.unbatch()]
predicted = model.predict(dataset)
actual = tf.stack(actual, axis=0)
predicted = tf.concat(predicted, axis=0)
predicted = tf.argmax(predicted, axis=1)
return actual, predicted
def plot_confusion_matrix(actual, predicted, labels, ds_type):
cm = tf.math.confusion_matrix(actual, predicted)
ax = sns.heatmap(cm, annot=True, fmt='g')
sns.set(rc={'figure.figsize':(12, 12)})
sns.set(font_scale=1.4)
ax.set_title('Confusion matrix of action recognition for ' + ds_type)
ax.set_xlabel('Predicted Action')
ax.set_ylabel('Actual Action')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
ax.xaxis.set_ticklabels(labels)
ax.yaxis.set_ticklabels(labels)
fg = FrameGenerator(subset_paths['train'], num_frames, training = True)
label_names = list(fg.class_ids_for_name.keys())
actual, predicted = get_actual_predicted_labels(test_ds)
plot_confusion_matrix(actual, predicted, label_names, 'test')
后续步骤#
现在,您已经对 MoViNet 模型以及如何利用各种 TensorFlow API(例如,用于迁移学习)有了一定的了解,请尝试将本教程中的代码用于您自己的数据集。数据不必限于视频数据。MRI 扫描等体数据也可与 3D CNN 一起使用。用于精神分裂症和控制分类的基于脑 MRI 的 3D 卷积神经网络中提到的 NUSDAT 和 IMH 数据集可能是 MRI 数据的两个此类来源。
特别是,使用本教程和其他视频数据与分类教程中使用的 FrameGenerator 类可以帮助您将数据加载到模型中。
要详细了解如何在 TensorFlow 中处理视频数据,请查看以下教程: