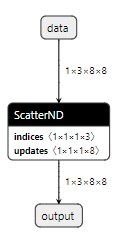
onnx ScatterND#
参考:ScatterND
ScatterND 算子涉及三个输入:秩为 r(r >= 1)的 data 张量,秩为 q(q >= 1)的 indices 张量,以及秩为 q + r - indices.shape[-1] - 1 的 updates 张量。该算子的输出是通过创建 data 输入的副本,然后根据 indices 指定的特定位置,将其值更新为 updates 张量中指定的值来产生的。它的输出形状与 data 的形状相同。
indices 是整数张量。设 k 为索引形状的最后一维,即 indices.shape[-1]。indices 被视为由 k 元组组成的 (q-1) 维张量,其中每个 k 元组都是对 data 的偏索引(partial-index)。因此, k 的值最多可以等于数据的秩。当 k 等于 data 的秩时,每个更新项指定了对张量单个元素的更新。当 k 小于 data 的秩时,每个更新项指定了对张量切片的更新。索引值可以是负数,按照从末尾开始倒数的通常惯例,但需要在有效范围内。
updates 被视为替换切片值的(q-1)维张量。因此,updates 形状的前(q-1)个维度必须与索引形状的前(q-1)个维度匹配。updates 的其余维度对应于替换切片值的维度。每个替换切片值是 (r-k) 维张量,对应于 data 的尾部 (r-k) 个维度。因此,updates 的形状必须等于 indices.shape[0:q-1] ++ data.shape[k:r-1],其中 ++ 表示形状的连接。
输出通过以下方程计算:
output = np.copy(data)
update_indices = indices.shape[:-1]
for idx in np.ndindex(update_indices):
output[indices[idx]] = updates[idx]
上述循环中的迭代顺序未指定。特别是,索引中不应有重复项:也就是说,如果 idx1 != idx2,那么 indices[idx1] != indices[idx2]。这确保了输出值不依赖于迭代顺序。
缩减(reduction)允许指定可选的缩减操作,该操作将所有 updates 张量中的值应用于指定 indices 的 output。在将 reduction 设置为“none”的情况下,索引中不应有重复项:也就是说,如果 idx1 != idx2,那么 indices[idx1] != indices[idx2]。这确保了输出值不依赖于迭代顺序。
当 reduction 设置为某个缩减函数 f 时,output 按以下方式计算:
output = np.copy(data)
update_indices = indices.shape[:-1]
for idx in np.ndindex(update_indices):
output[indices[idx]] = f(output[indices[idx]], updates[idx])
其中 f 是指定的加法(+),乘法(*),最大值(max)或最小值(min)。
这个算子是 GatherND 的逆运算。
示例1:
data = [1, 2, 3, 4, 5, 6, 7, 8]
indices = [[4], [3], [1], [7]]
updates = [9, 10, 11, 12]
output = [1, 11, 3, 10, 9, 6, 7, 12]
示例2:
data = [[[1, 2, 3, 4], [5, 6, 7, 8], [8, 7, 6, 5], [4, 3, 2, 1]],
[[1, 2, 3, 4], [5, 6, 7, 8], [8, 7, 6, 5], [4, 3, 2, 1]],
[[8, 7, 6, 5], [4, 3, 2, 1], [1, 2, 3, 4], [5, 6, 7, 8]],
[[8, 7, 6, 5], [4, 3, 2, 1], [1, 2, 3, 4], [5, 6, 7, 8]]]
indices = [[0], [2]]
updates = [[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]]]
output = [[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[1, 2, 3, 4], [5, 6, 7, 8], [8, 7, 6, 5], [4, 3, 2, 1]],
[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3], [4, 4, 4, 4]],
[[8, 7, 6, 5], [4, 3, 2, 1], [1, 2, 3, 4], [5, 6, 7, 8]]]
%cd ../../..
import set_env
from d2py.utils.file import mkdir
temp_dir = ".temp"
mkdir(temp_dir)
/media/pc/data/lxw/ai/tvm-book/doc/tutorials/frontend
import torch
from torch import nn
# class Model(nn.Module):
# def forward(self, x):
# x[0] = x[0] + 1
# return x
class Model(nn.Module):
def forward(self, x):
x[:, 0, 1] = 1.
return x
shape = 1, 3, 8, 8
x = torch.rand(*shape)
torch_model = Model()
# 导出模型
output_name = "ScatterND"
torch.onnx.export(
torch_model, # torch 模型
x, # 模型输入或者对于多个输入,使用元组
f"{temp_dir}/{output_name}.onnx", # 模型保存的位置(可以是文件或类似文件的对象)
export_params=True, # 将训练后的参数权重存储在模型文件内
opset_version=17, # 导出模型的 ONNX 版本
do_constant_folding=True, # 是否执行常量折叠以进行优化
verbose=True,
input_names = ['data'], # 模型的输入名称
output_names = ['output'], # 模型的输出名称
# dynamic_axes={'data' : {0 : 'batch_size'}, # 可变长度的轴
# 'output' : {0 : 'batch_size'}}
)
Exported graph: graph(%data : Float(1, 3, 8, 8, strides=[192, 64, 8, 1], requires_grad=0, device=cpu)):
%/Constant_output_0 : Long(device=cpu) = onnx::Constant[value={0}, onnx_name="/Constant"](), scope: __main__.Model::
%/Constant_1_output_0 : Long(device=cpu) = onnx::Constant[value={1}, onnx_name="/Constant_1"](), scope: __main__.Model::
%/Gather_output_0 : Float(1, 8, 8, strides=[192, 8, 1], requires_grad=0, device=cpu) = onnx::Gather[axis=1, onnx_name="/Gather"](%data, %/Constant_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Gather_1_output_0 : Float(1, 8, strides=[192, 1], requires_grad=0, device=cpu) = onnx::Gather[axis=1, onnx_name="/Gather_1"](%/Gather_output_0, %/Constant_1_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_2_output_0 : Float(1, 1, strides=[1, 1], device=cpu) = onnx::Constant[value={1}, onnx_name="/Constant_2"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Shape_output_0 : Long(2, strides=[1], device=cpu) = onnx::Shape[onnx_name="/Shape"](%/Gather_1_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Expand_output_0 : Float(1, 8, strides=[192, 1], requires_grad=0, device=cpu) = onnx::Expand[onnx_name="/Expand"](%/Constant_2_output_0, %/Shape_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_3_output_0 : Long(1, strides=[1], requires_grad=0, device=cpu) = onnx::Constant[value={1}, onnx_name="/Constant_3"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_4_output_0 : Long(1, 1, 1, strides=[1, 1, 1], requires_grad=0, device=cpu) = onnx::Constant[value={0}, onnx_name="/Constant_4"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_5_output_0 : Long(1, 1, strides=[1, 1], requires_grad=0, device=cpu) = onnx::Constant[value={0}, onnx_name="/Constant_5"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_6_output_0 : Long(3, strides=[1], requires_grad=0, device=cpu) = onnx::Constant[value= 1 1 1 [ CPULongType{3} ], onnx_name="/Constant_6"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_7_output_0 : Long(1, strides=[1], requires_grad=0, device=cpu) = onnx::Constant[value={3}, onnx_name="/Constant_7"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/ConstantOfShape_output_0 : Long(3, strides=[1], device=cpu) = onnx::ConstantOfShape[value={1}, onnx_name="/ConstantOfShape"](%/Constant_7_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_8_output_0 : Long(requires_grad=0, device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_8"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Mul_output_0 : Long(3, strides=[1], device=cpu) = onnx::Mul[onnx_name="/Mul"](%/ConstantOfShape_output_0, %/Constant_8_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Equal_output_0 : Bool(3, strides=[1], device=cpu) = onnx::Equal[onnx_name="/Equal"](%/Constant_6_output_0, %/Mul_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Where_output_0 : Long(3, strides=[1], device=cpu) = onnx::Where[onnx_name="/Where"](%/Equal_output_0, %/ConstantOfShape_output_0, %/Constant_6_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Expand_1_output_0 : Long(1, 1, 1, strides=[1, 1, 1], device=cpu) = onnx::Expand[onnx_name="/Expand_1"](%/Constant_4_output_0, %/Where_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_9_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_9"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Unsqueeze_output_0 : Long(1, 1, 1, 1, strides=[1, 1, 1, 1], device=cpu) = onnx::Unsqueeze[onnx_name="/Unsqueeze"](%/Expand_1_output_0, %/Constant_9_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_10_output_0 : Long(1, strides=[1], requires_grad=0, device=cpu) = onnx::Constant[value={3}, onnx_name="/Constant_10"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/ConstantOfShape_1_output_0 : Long(3, strides=[1], device=cpu) = onnx::ConstantOfShape[value={1}, onnx_name="/ConstantOfShape_1"](%/Constant_10_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_11_output_0 : Long(requires_grad=0, device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_11"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Mul_1_output_0 : Long(3, strides=[1], device=cpu) = onnx::Mul[onnx_name="/Mul_1"](%/ConstantOfShape_1_output_0, %/Constant_11_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Equal_1_output_0 : Bool(3, strides=[1], device=cpu) = onnx::Equal[onnx_name="/Equal_1"](%/Constant_6_output_0, %/Mul_1_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Where_1_output_0 : Long(3, strides=[1], device=cpu) = onnx::Where[onnx_name="/Where_1"](%/Equal_1_output_0, %/ConstantOfShape_1_output_0, %/Constant_6_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Expand_2_output_0 : Long(1, 1, 1, strides=[1, 1, 1], device=cpu) = onnx::Expand[onnx_name="/Expand_2"](%/Constant_5_output_0, %/Where_1_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_12_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_12"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Unsqueeze_1_output_0 : Long(1, 1, 1, 1, strides=[1, 1, 1, 1], device=cpu) = onnx::Unsqueeze[onnx_name="/Unsqueeze_1"](%/Expand_2_output_0, %/Constant_12_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_13_output_0 : Long(1, strides=[1], requires_grad=0, device=cpu) = onnx::Constant[value={3}, onnx_name="/Constant_13"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/ConstantOfShape_2_output_0 : Long(3, strides=[1], device=cpu) = onnx::ConstantOfShape[value={1}, onnx_name="/ConstantOfShape_2"](%/Constant_13_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_14_output_0 : Long(requires_grad=0, device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_14"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Mul_2_output_0 : Long(3, strides=[1], device=cpu) = onnx::Mul[onnx_name="/Mul_2"](%/ConstantOfShape_2_output_0, %/Constant_14_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Equal_2_output_0 : Bool(3, strides=[1], device=cpu) = onnx::Equal[onnx_name="/Equal_2"](%/Constant_6_output_0, %/Mul_2_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Where_2_output_0 : Long(3, strides=[1], device=cpu) = onnx::Where[onnx_name="/Where_2"](%/Equal_2_output_0, %/ConstantOfShape_2_output_0, %/Constant_6_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Expand_3_output_0 : Long(1, 1, 1, strides=[1, 1, 1], device=cpu) = onnx::Expand[onnx_name="/Expand_3"](%/Constant_3_output_0, %/Where_2_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_15_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={-1}, onnx_name="/Constant_15"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Unsqueeze_2_output_0 : Long(1, 1, 1, 1, strides=[1, 1, 1, 1], device=cpu) = onnx::Unsqueeze[onnx_name="/Unsqueeze_2"](%/Expand_3_output_0, %/Constant_15_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Concat_output_0 : Long(1, 1, 1, 3, strides=[3, 3, 3, 1], device=cpu) = onnx::Concat[axis=-1, onnx_name="/Concat"](%/Unsqueeze_output_0, %/Unsqueeze_1_output_0, %/Unsqueeze_2_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Shape_1_output_0 : Long(4, strides=[1], device=cpu) = onnx::Shape[onnx_name="/Shape_1"](%data), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_16_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={0}, onnx_name="/Constant_16"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_17_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={3}, onnx_name="/Constant_17"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Constant_18_output_0 : Long(1, strides=[1], device=cpu) = onnx::Constant[value={9223372036854775807}, onnx_name="/Constant_18"](), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Slice_output_0 : Long(1, strides=[1], device=cpu) = onnx::Slice[onnx_name="/Slice"](%/Shape_1_output_0, %/Constant_17_output_0, %/Constant_18_output_0, %/Constant_16_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Concat_1_output_0 : Long(4, strides=[1], device=cpu) = onnx::Concat[axis=0, onnx_name="/Concat_1"](%/Constant_6_output_0, %/Slice_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%/Reshape_output_0 : Float(1, 1, 1, 8, strides=[8, 8, 8, 1], device=cpu) = onnx::Reshape[allowzero=0, onnx_name="/Reshape"](%/Expand_output_0, %/Concat_1_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
%output : Float(1, 3, 8, 8, strides=[192, 64, 8, 1], requires_grad=0, device=cpu) = onnx::ScatterND[onnx_name="/ScatterND"](%data, %/Concat_output_0, %/Reshape_output_0), scope: __main__.Model:: # /tmp/ipykernel_1545034/3422673722.py:11:0
return (%output)
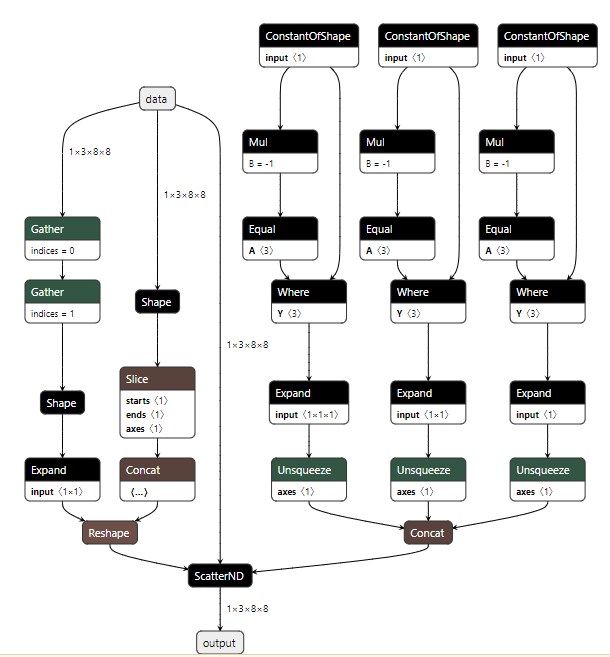
import onnx
import tvm
from tvm import relay
onnx_model = onnx.load(f"{temp_dir}/{output_name}.onnx")
mod, params = relay.frontend.from_onnx(onnx_model, {"data": shape}, freeze_params=True)
mod.show()
def @main(%data: Tensor[(1, 3, 8, 8), float32] /* ty=Tensor[(1, 3, 8, 8), float32] span=/Gather.data:0:0 */) -> Tensor[(1, 3, 8, 8), float32] {
scatter_nd(%data, meta[relay.Constant][0] /* ty=Tensor[(3, 1, 1, 1), int64] span=/ScatterND:0:0 */, meta[relay.Constant][1] /* ty=Tensor[(1, 1, 1, 8), float32] span=/Reshape:0:0 */) /* ty=Tensor[(1, 3, 8, 8), float32] span=/ScatterND:0:0 */
}
# with tvm.transform.PassContext(opt_level=3):
# with relay.quantize.qconfig(
# skip_conv_layers=[],
# # calibrate_mode="kl_divergence",
# weight_scale="max",
# # round_for_shift=True,
# # rounding="TONEAREST", # "UPWARD" or "TONEAREST"
# # calibrate_skip_layers=[],
# skip_dense_layer=False,
# ):
# qmod = relay.quantize.quantize(mod, params)
# qmod.show()
try:
import onnx
import onnxsim
import onnx
import tvm
from tvm import relay
# 模型化简
model_onnx = onnx.load(f"{temp_dir}/{output_name}.onnx")
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
onnx.save(model_onnx, f"{temp_dir}/{output_name}-s.onnx")
onnx_model = onnx.load(f"{temp_dir}/{output_name}-s.onnx")
mod, params = relay.frontend.from_onnx(onnx_model, {"data": shape}, freeze_params=True)
mod.show()
except:
...
def @main(%data: Tensor[(1, 3, 8, 8), float32] /* ty=Tensor[(1, 3, 8, 8), float32] span=/ScatterND.data:0:0 */) -> Tensor[(1, 3, 8, 8), float32] {
scatter_nd(%data, meta[relay.Constant][0] /* ty=Tensor[(3, 1, 1, 1), int64] span=/ScatterND:0:0 */, meta[relay.Constant][1] /* ty=Tensor[(1, 1, 1, 8), float32] span=/ScatterND./Reshape_output_0:0:0 */) /* ty=Tensor[(1, 3, 8, 8), float32] span=/ScatterND:0:0 */
}