MSCRunner#
MSC 中每个 runtime 系统有其对应的 MSCRunner。MSCRunner 被 MSCManager 管理,并暴露隔离具体 runtime 类型的 forward 接口,用于运行数据。例如:
%cd ../..
import set_env
/media/pc/data/lxw/ai/tvm-book/doc/tutorials
import numpy as np
import torch
from torch import fx
from torchvision.models import resnet50
from tvm.relax.frontend.torch import from_fx
from tvm.contrib.msc.framework.tvm.runtime import TVMRunner
from tvm.contrib.msc.framework.torch.runtime import TorchRunner
from tvm.contrib.msc.core import utils as msc_utils
model = resnet50().eval()
input_info = [([1, 3, 224, 224], "float32")]
datas = [np.random.rand(*i[0]).astype(i[1]) for i in input_info]
graph_model = fx.symbolic_trace(model)
with torch.no_grad():
mod = from_fx(graph_model, input_info)
构建并运行 TorchRunner#
# build and run by torch
workspace = msc_utils.set_workspace(msc_utils.msc_dir(".temp/torch_test"))
log_path = workspace.relpath("MSC_LOG", keep_history=False)
msc_utils.set_global_logger("critical", log_path)
torch_runner = TorchRunner(mod)
torch_runner.build()
outputs = torch_runner.run(datas)
for k, v in outputs.items():
print(f"torch output {k}:{msc_utils.inspect_array(v)}")
workspace.destory()
torch output matmul:<torch @cpu>[1;1000,float32] Max 24.3415, Min -29.508, Avg -0.119518
/media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/torch/codegen/codegen.py:74: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(folder.relpath(graph.name + ".pth"))
构建并运行 TVMRunner#
workspace = msc_utils.set_workspace(msc_utils.msc_dir(".temp/tvm_test"))
log_path = workspace.relpath("MSC_LOG", keep_history=False)
msc_utils.set_global_logger("critical", log_path)
tvm_runner = TVMRunner(mod)
tvm_runner.build()
outputs = tvm_runner.run(datas)
for k, v in outputs.items():
print(f"tvm output {k}:{msc_utils.inspect_array(v)}")
workspace.destory()
tvm output matmul:<tvm @cpu>[1;1000,float32] Max 24.3415, Min -29.508, Avg -0.119518
MSCRunner 屏蔽了 runtime 类型的差异,可以让 MSCManger 专注于流程控制而不需要处理 runtime 的细节。一个 MSCRunner 中包含 1 到多个 MSCGraph (BYOC 的 Runner 可以有多个 MSCGraph)以及 MSCTools。核心方法是 build (构建 runnable 对象)和 run(跑数据)
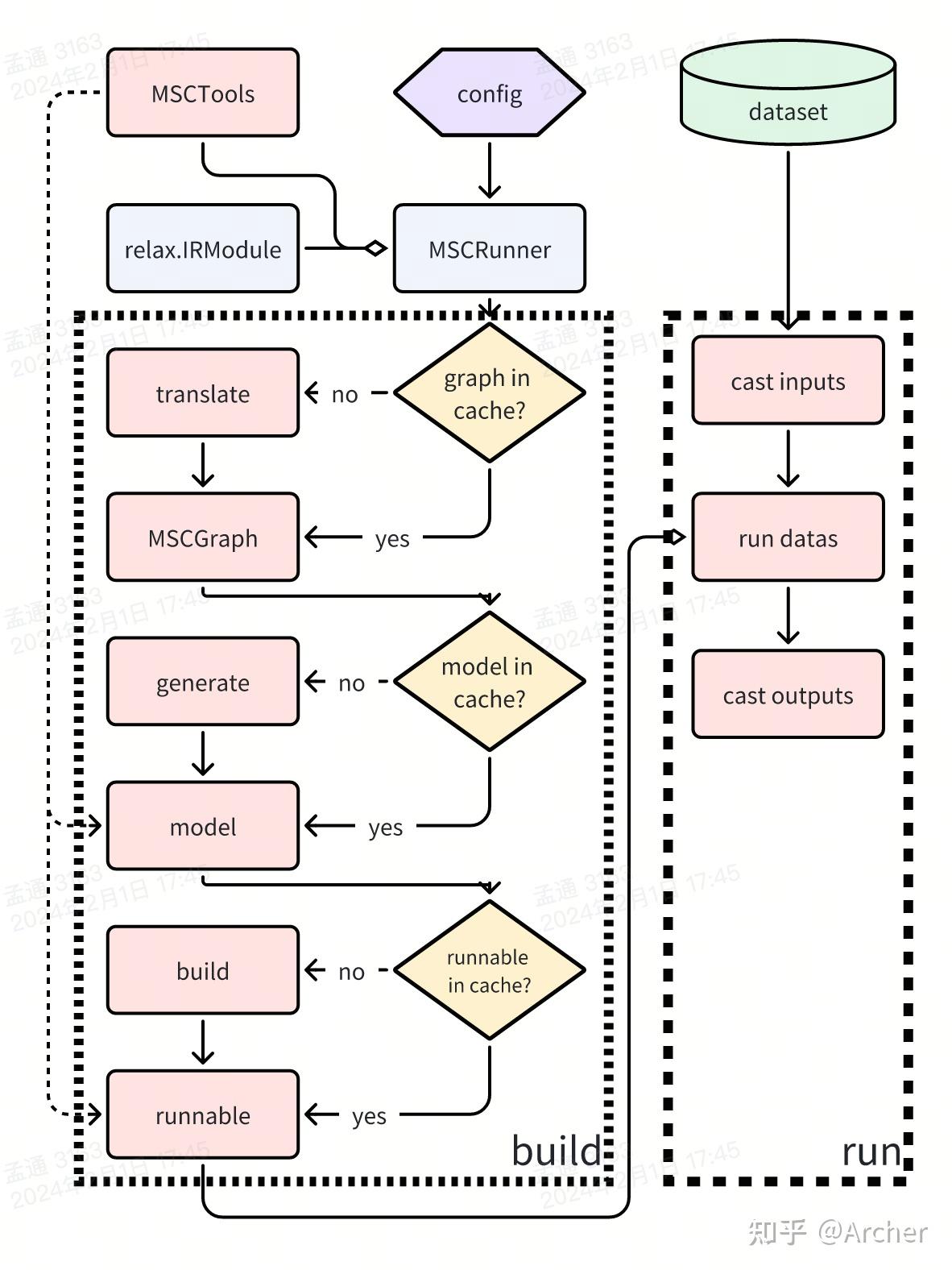
MSCRunner.build() 构建 runnable 对象#
build方法用于构建 runnable 对象,runnable 对象可以调用 MSCTools 对 runtime 过程进行控制(例如稀疏化过程的 apply mask,量化过程的 q/dq 运算等),并且可以被 runtime 系统直接加载。(例如 TorchRunner 对应的 runnable 对象是 torch.nn.Module,TVMRunner 对应的 runnable 是 tvm.VirtualMachine)
build过程产生三个阶段的object,每个阶段都会尝试从cache中读取,以此减少构建时间,每个阶段的任务为:
IRModule -> MSCGraph:通过translate模块的from_relax将传入的relax IRModule构建为MSCGraph,此过程参考test_graph_buildMSCGraph -> model:调用Codegen将MSCGraph转换成不同runtime中的model,注意model并不一定是runnable对象,例如tensorflow中model是tf.Graph,而runnable为Session;tvm中model是relax.IRModule,而runnable为VirtualMachine。将model和runnable分开成两个阶段主要考虑不同框架中计算图描述和运行时对象可能并不相同。此过程Unittest参考:test_translate_relax.py、test_translate_torch.py、test_translate_tensorflow.py。如果创建了MSCTool,Codegen过程根据tools的配置插入埋点对tensor进行操作,在构建model的时候会对计算图进行改造(例如插入q/dq节点,对weights添加mask等)model -> runnable:根据配置将model转换为runnable对象,runnable对象可以控制MSCTools在runtime过程中对压缩行为进行控制。这部分逻辑不包含MSC特有逻辑,主要是调用框架的build方法将计算图变成可执行对象。
MSCRunner.run() 执行数据#
直接调用 MSCRunner.build() 阶段得到的runnable对象跑数据,但由于不同runnable支持的输入数据格式不同,需要在数据输入和数据导出的时候进行两次cast,将MSC标准数据(np.array)和框架中的数据格式互相转换。默认情况下run函数输入输出均为dict<str:np.array>格式。
MSCRunner 测试#
import numpy as np
import torch
from torch import fx
from tvm.contrib.msc.framework.tensorflow import tf_v1
import tvm.testing
from tvm.relax.frontend.torch import from_fx
from tvm.contrib.msc.framework.tvm.runtime import TVMRunner
from tvm.contrib.msc.framework.torch.runtime import TorchRunner
from tvm.contrib.msc.framework.tensorrt.runtime import TensorRTRunner
from tvm.contrib.msc.framework.tensorflow.frontend import from_tensorflow
from tvm.contrib.msc.framework.tensorflow.runtime import TensorflowRunner
from tvm.contrib.msc.core import utils as msc_utils
2024-09-05 17:46:06.336593: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-09-05 17:46:06.353441: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-09-05 17:46:06.359063: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-09-05 17:46:06.374053: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-09-05 17:46:07.518407: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
def _get_torch_model(name, training=False):
"""Get model from torch vision"""
# pylint: disable=import-outside-toplevel
try:
import torchvision
model = getattr(torchvision.models, name)()
if training:
model = model.train()
else:
model = model.eval()
return model
except: # pylint: disable=bare-except
print("please install torchvision package")
return None
def _get_tf_graph():
"""Get tensorflow graphdef"""
# pylint: disable=import-outside-toplevel
try:
import tvm.relay.testing.tf as tf_testing
tf_graph = tf_v1.Graph()
with tf_graph.as_default():
graph_def = tf_testing.get_workload(
"https://storage.googleapis.com/mobilenet_v2/checkpoints/mobilenet_v2_1.4_224.tgz",
"mobilenet_v2_1.4_224_frozen.pb",
)
# Call the utility to import the graph definition into default graph.
graph_def = tf_testing.ProcessGraphDefParam(graph_def)
return tf_graph, graph_def
except: # pylint: disable=bare-except
print("please install tensorflow package")
return None, None
def _test_from_torch(runner_cls, device, training=False, atol=1e-1, rtol=1e-1):
"""Test runner from torch model"""
torch_model = _get_torch_model("resnet50", training)
if torch_model:
path = "test_runner_torch_{}_{}".format(runner_cls.__name__, device)
workspace = msc_utils.set_workspace(msc_utils.msc_dir(path))
log_path = workspace.relpath("MSC_LOG", keep_history=False)
msc_utils.set_global_logger("critical", log_path)
input_info = [([1, 3, 224, 224], "float32")]
datas = [np.random.rand(*i[0]).astype(i[1]) for i in input_info]
torch_datas = [torch.from_numpy(d) for d in datas]
graph_model = fx.symbolic_trace(torch_model)
with torch.no_grad():
golden = torch_model(*torch_datas)
mod = from_fx(graph_model, input_info)
runner = runner_cls(mod, device=device, training=training)
runner.build()
outputs = runner.run(datas, ret_type="list")
golden = [msc_utils.cast_array(golden)]
workspace.destory()
for gol_r, out_r in zip(golden, outputs):
tvm.testing.assert_allclose(gol_r, msc_utils.cast_array(out_r), atol=atol, rtol=rtol)
for dev in ["cpu", "cuda"]:
for training in [True, False]:
_test_from_torch(TVMRunner, dev, training=training)
_test_from_torch(TorchRunner, dev, training=training)
/media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/torch/codegen/codegen.py:74: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(folder.relpath(graph.name + ".pth"))
/media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/torch/codegen/codegen.py:74: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(folder.relpath(graph.name + ".pth"))
/media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/torch/codegen/codegen.py:74: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(folder.relpath(graph.name + ".pth"))
/media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/torch/codegen/codegen.py:74: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(folder.relpath(graph.name + ".pth"))
# _test_from_torch(TensorRTRunner, "cuda", atol=1e-1, rtol=1e-1)
tf_graph, graph_def = _get_tf_graph()
if tf_graph and graph_def:
path = ".temp/test_runner_tf"
workspace = msc_utils.set_workspace(msc_utils.msc_dir(path))
log_path = workspace.relpath("MSC_LOG", keep_history=False)
msc_utils.set_global_logger("critical", log_path)
data = np.random.uniform(size=(1, 224, 224, 3)).astype("float32")
out_name = "MobilenetV2/Predictions/Reshape_1:0"
# get golden
with tf_v1.Session(graph=tf_graph) as sess:
golden = sess.run([out_name], {"input:0": data})
# get outputs
shape_dict = {"input": data.shape}
mod, _ = from_tensorflow(graph_def, shape_dict, [out_name], as_msc=False)
runner = TensorflowRunner(mod)
runner.build()
outputs = runner.run([data], ret_type="list")
workspace.destory()
for gol_r, out_r in zip(golden, outputs):
tvm.testing.assert_allclose(gol_r, msc_utils.cast_array(out_r), atol=1e-3, rtol=1e-3)
WARNING:tensorflow:From /media/pc/data/lxw/ai/tvm/python/tvm/relay/testing/tf.py:282: FastGFile.__init__ (from tensorflow.python.platform.gfile) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.gfile.GFile.
2024-09-05 17:47:44.928138: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2021] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 21406 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3090, pci bus id: 0000:03:00.0, compute capability: 8.6
2024-09-05 17:47:44.928713: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2021] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 9796 MB memory: -> device: 1, name: NVIDIA GeForce RTX 2080 Ti, pci bus id: 0000:81:00.0, compute capability: 7.5
2024-09-05 17:47:44.950373: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:388] MLIR V1 optimization pass is not enabled
2024-09-05 17:47:45.762472: I external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:531] Loaded cuDNN version 8907
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
W0000 00:00:1725529666.090695 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.127222 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.127753 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.128264 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.128771 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.147542 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.150366 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.152795 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.155298 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.155798 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.243736 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.247140 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.250246 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.250695 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.251122 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.251545 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.251962 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.273095 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.276482 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.280142 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.283291 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.286353 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.313836 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.314450 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.317237 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.317830 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.320924 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.323952 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.324507 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.324991 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.328282 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
W0000 00:00:1725529666.331261 1576870 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[7], line 16
14 mod, _ = from_tensorflow(graph_def, shape_dict, [out_name], as_msc=False)
15 runner = TensorflowRunner(mod)
---> 16 runner.build()
17 outputs = runner.run([data], ret_type="list")
18 workspace.destory()
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/core/runtime/runner.py:249, in BaseRunner.build(self, cache_dir, force_build, disable_tools)
246 else:
247 # Generate normal model
248 self._graphs, self._weights = self.reset_tools(tools=tools, cache_dir=cache_dir)
--> 249 self._model = self.generate_model()
250 build_msg += "Generate "
252 # Add tool message
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/core/runtime/runner.py:441, in BaseRunner.generate_model(self, apply_hooks)
439 for hook in self._generate_config.get("pre_hooks", []):
440 graphs, weights = self._apply_hook("before generate", hook, graphs, weights)
--> 441 model = self._generate_model(graphs, weights)
442 if apply_hooks:
443 for hook in self._generate_config.get("post_hooks", []):
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/tensorflow/runtime/runner.py:112, in TensorflowRunner._generate_model(self, graphs, weights)
110 self._tf_graph = tf_v1.Graph()
111 with self._tf_graph.as_default():
--> 112 self._tf_outputs = super()._generate_model(graphs, weights)
113 return self._tf_graph
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/core/runtime/runner.py:1229, in ModelRunner._generate_model(self, graphs, weights)
1213 def _generate_model(self, graphs: List[MSCGraph], weights: Dict[str, tvm.nd.array]) -> Any:
1214 """Codegen the model according to framework
1215
1216 Parameters
(...)
1226 The runnable model
1227 """
-> 1229 return self.codegen_func(
1230 graphs[0],
1231 weights,
1232 codegen_config=self._generate_config.get("codegen"),
1233 print_config=self._generate_config.get("print"),
1234 build_folder=self._generate_config["build_folder"],
1235 plugin=self._plugin,
1236 )
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/framework/tensorflow/codegen/codegen.py:72, in to_tensorflow(graph, weights, codegen_config, print_config, build_folder, plugin)
70 if plugin:
71 model_args = model_args + [plugin]
---> 72 return codegen.load(model_args, pre_load=_save_weights)
File /media/pc/data/lxw/ai/tvm/python/tvm/contrib/msc/core/codegen/codegen.py:118, in CodeGen.load(self, inputs, pre_load, post_load, build_model)
116 elif self._code_format == "python":
117 builder = msc_utils.load_callable(self._graph.name + ".py:" + self._graph.name)
--> 118 obj = builder(*inputs)
119 else:
120 raise NotImplementedError(
121 "Code format {} is not supported".format(self._code_format)
122 )
File main.py:127, in main(res_0, weights)
File /media/pc/data/lxw/envs/anaconda3x/envs/xxx/lib/python3.12/site-packages/tensorflow/python/util/lazy_loader.py:207, in KerasLazyLoader.__getattr__(self, item)
200 raise AttributeError(
201 "`tf.compat.v2.keras` is not available with Keras 3. Just use "
202 "`import keras` instead."
203 )
204 elif self._tfll_submodule and self._tfll_submodule.startswith(
205 "__internal__.legacy."
206 ):
--> 207 raise AttributeError(
208 f"`{item}` is not available with Keras 3."
209 )
210 module = self._load()
211 return getattr(module, item)
AttributeError: `batch_normalization` is not available with Keras 3.