BN+conv#
%cd ../../..
import set_env
from d2py.utils.file import mkdir
temp_dir = ".temp"
mkdir(temp_dir)
/media/pc/data/lxw/ai/tvm-book/doc/tutorials/frontend
import torch
from torch import nn
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 1, 1, 0, bias=False, groups=1)
self.act1 = nn.ReLU()
self.bn1 = nn.BatchNorm2d(num_features=16)
self.conv2 = nn.Conv2d(16, 32, 1, 1, 0, bias=False, groups=1)
def forward(self, x):
x = self.conv1(x)
x = self.act1(x)
x = self.bn1(x)
x = self.conv2(x)
return x
shape = 1, 3, 32, 32
x = torch.rand(*shape)
torch_model = Model()
# 导出模型
output_name = "bn-conv"
torch.onnx.export(
torch_model, # torch 模型
x, # 模型输入或者对于多个输入,使用元组
f"{temp_dir}/{output_name}.onnx", # 模型保存的位置(可以是文件或类似文件的对象)
export_params=True, # 将训练后的参数权重存储在模型文件内
opset_version=17, # 导出模型的 ONNX 版本
do_constant_folding=True, # 是否执行常量折叠以进行优化
input_names = ['data'], # 模型的输入名称
output_names = ['output'], # 模型的输出名称
# keep_initializers_as_inputs=True,
# export_modules_as_functions=True,
verbose=True,
dynamic_axes={'data' : {0 : 'batch_size'}, # 可变长度的轴
'output' : {0 : 'batch_size'}}
)
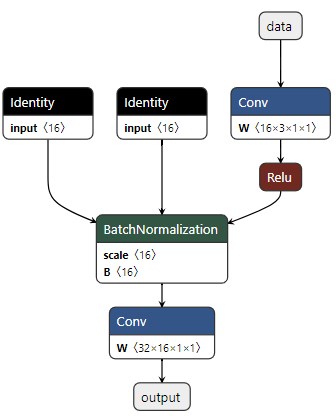
Exported graph: graph(%data : Float(*, 3, 32, 32, strides=[3072, 1024, 32, 1], requires_grad=0, device=cpu),
%conv1.weight : Float(16, 3, 1, 1, strides=[3, 1, 1, 1], requires_grad=1, device=cpu),
%bn1.weight : Float(16, strides=[1], requires_grad=1, device=cpu),
%bn1.bias : Float(16, strides=[1], requires_grad=1, device=cpu),
%conv2.weight : Float(32, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cpu)):
%bn1.running_var : Float(16, strides=[1], requires_grad=0, device=cpu) = onnx::Identity(%bn1.weight)
%bn1.running_mean : Float(16, strides=[1], requires_grad=0, device=cpu) = onnx::Identity(%bn1.bias)
%/conv1/Conv_output_0 : Float(*, 16, 32, 32, strides=[16384, 1024, 32, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/conv1/Conv"](%data, %conv1.weight), scope: __main__.Model::/torch.nn.modules.conv.Conv2d::conv1 # /media/pc/data/tmp/cache/conda/envs/xin/lib/python3.12/site-packages/torch/nn/modules/conv.py:456:0
%/act1/Relu_output_0 : Float(*, 16, 32, 32, strides=[16384, 1024, 32, 1], requires_grad=1, device=cpu) = onnx::Relu[onnx_name="/act1/Relu"](%/conv1/Conv_output_0), scope: __main__.Model::/torch.nn.modules.activation.ReLU::act1 # /media/pc/data/tmp/cache/conda/envs/xin/lib/python3.12/site-packages/torch/nn/functional.py:1473:0
%/bn1/BatchNormalization_output_0 : Float(*, 16, 32, 32, strides=[16384, 1024, 32, 1], requires_grad=1, device=cpu) = onnx::BatchNormalization[epsilon=1.0000000000000001e-05, momentum=0.90000000000000002, training_mode=0, onnx_name="/bn1/BatchNormalization"](%/act1/Relu_output_0, %bn1.weight, %bn1.bias, %bn1.running_mean, %bn1.running_var), scope: __main__.Model::/torch.nn.modules.batchnorm.BatchNorm2d::bn1 # /media/pc/data/tmp/cache/conda/envs/xin/lib/python3.12/site-packages/torch/nn/functional.py:2482:0
%output : Float(*, 32, 32, 32, strides=[32768, 1024, 32, 1], requires_grad=1, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/conv2/Conv"](%/bn1/BatchNormalization_output_0, %conv2.weight), scope: __main__.Model::/torch.nn.modules.conv.Conv2d::conv2 # /media/pc/data/tmp/cache/conda/envs/xin/lib/python3.12/site-packages/torch/nn/modules/conv.py:456:0
return (%output)
import onnx
import tvm
from tvm import relay
onnx_model = onnx.load(f"{temp_dir}/{output_name}.onnx")
mod, params = relay.frontend.from_onnx(onnx_model, {"data": shape}, freeze_params=True)
# with tvm.transform.PassContext(opt_level=3):
# mod = relay.quantize.prerequisite_optimize(mod, params)
mod.show()
def @main(%data: Tensor[(1, 3, 32, 32), float32] /* ty=Tensor[(1, 3, 32, 32), float32] span=/conv1/Conv.data:0:0 */) -> Tensor[(1, 32, 32, 32), float32] {
%0 = nn.conv2d(%data, meta[relay.Constant][0] /* ty=Tensor[(16, 3, 1, 1), float32] span=/conv1/Conv.conv1.weight:0:0 */, padding=[0, 0, 0, 0], channels=16, kernel_size=[1, 1]) /* ty=Tensor[(1, 16, 32, 32), float32] span=/conv1/Conv:0:0 */;
%1 = nn.relu(%0) /* ty=Tensor[(1, 16, 32, 32), float32] span=/act1/Relu:0:0 */;
%2 = nn.batch_norm(%1, meta[relay.Constant][1] /* ty=Tensor[(16), float32] span=Identity_0.bn1.weight:0:0 */, meta[relay.Constant][2] /* ty=Tensor[(16), float32] span=Identity_1.bn1.bias:0:0 */, meta[relay.Constant][3] /* ty=Tensor[(16), float32] span=Identity_1:0:0 */, meta[relay.Constant][4] /* ty=Tensor[(16), float32] span=Identity_0:0:0 */) /* ty=(Tensor[(1, 16, 32, 32), float32], Tensor[(16), float32], Tensor[(16), float32]) span=/bn1/BatchNormalization:0:0 */;
%3 = %2.0 /* ty=Tensor[(1, 16, 32, 32), float32] span=/bn1/BatchNormalization:0:0 */;
nn.conv2d(%3, meta[relay.Constant][5] /* ty=Tensor[(32, 16, 1, 1), float32] span=/conv2/Conv.conv2.weight:0:0 */, padding=[0, 0, 0, 0], channels=32, kernel_size=[1, 1]) /* ty=Tensor[(1, 32, 32, 32), float32] span=/conv2/Conv:0:0 */
}
with tvm.transform.PassContext(opt_level=3):
with relay.quantize.qconfig(
skip_conv_layers=[],
# calibrate_mode="kl_divergence",
weight_scale="max",
# round_for_shift=True,
# rounding="TONEAREST", # "UPWARD" or "TONEAREST"
# calibrate_skip_layers=[],
skip_dense_layer=False,
):
qmod = relay.quantize.quantize(mod, params)
qmod.show()
def @main(%data: Tensor[(1, 3, 32, 32), float32] /* ty=Tensor[(1, 3, 32, 32), float32] span=/conv1/Conv.data:0:0 */) -> Tensor[(1, 32, 32, 32), float32] {
%0 = multiply(%data, 16f /* ty=float32 */) /* ty=Tensor[(1, 3, 32, 32), float32] */;
%1 = round(%0) /* ty=Tensor[(1, 3, 32, 32), float32] */;
%2 = clip(%1, a_min=-127f, a_max=127f) /* ty=Tensor[(1, 3, 32, 32), float32] */;
%3 = cast(%2, dtype="int8") /* ty=Tensor[(1, 3, 32, 32), int8] */;
%4 = nn.conv2d(%3, meta[relay.Constant][0] /* ty=Tensor[(16, 3, 1, 1), int8] */, padding=[0, 0, 0, 0], channels=16, kernel_size=[1, 1], out_dtype="int32") /* ty=Tensor[(1, 16, 32, 32), int32] */;
%5 = nn.relu(%4) /* ty=Tensor[(1, 16, 32, 32), int32] */;
%6 = fixed_point_multiply(%5, multiplier=0, shift=0) /* ty=Tensor[(1, 16, 32, 32), int32] */;
%7 = cast(%6, dtype="int32") /* ty=Tensor[(1, 16, 32, 32), int32] */;
%8 = add(%7, meta[relay.Constant][1] /* ty=Tensor[(16, 1, 1), int32] */) /* ty=Tensor[(1, 16, 32, 32), int32] */;
%9 = cast(%8, dtype="int64") /* ty=Tensor[(1, 16, 32, 32), int64] */;
%10 = fixed_point_multiply(%9, multiplier=0, shift=0) /* ty=Tensor[(1, 16, 32, 32), int64] */;
%11 = clip(%10, a_min=-127f, a_max=127f) /* ty=Tensor[(1, 16, 32, 32), int64] */;
%12 = cast(%11, dtype="int32") /* ty=Tensor[(1, 16, 32, 32), int32] */;
%13 = cast(%12, dtype="int8") /* ty=Tensor[(1, 16, 32, 32), int8] */;
%14 = annotation.stop_fusion(%13) /* ty=Tensor[(1, 16, 32, 32), int8] */;
%15 = nn.conv2d(%14, meta[relay.Constant][2] /* ty=Tensor[(32, 16, 1, 1), int8] */, padding=[0, 0, 0, 0], channels=32, kernel_size=[1, 1], out_dtype="int32") /* ty=Tensor[(1, 32, 32, 32), int32] */;
%16 = cast(%15, dtype="int64") /* ty=Tensor[(1, 32, 32, 32), int64] */;
%17 = fixed_point_multiply(%16, multiplier=2146285056, shift=-9) /* ty=Tensor[(1, 32, 32, 32), int64] */;
%18 = clip(%17, a_min=-127f, a_max=127f) /* ty=Tensor[(1, 32, 32, 32), int64] */;
%19 = cast(%18, dtype="int32") /* ty=Tensor[(1, 32, 32, 32), int32] */;
%20 = cast(%19, dtype="int8") /* ty=Tensor[(1, 32, 32, 32), int8] */;
%21 = annotation.stop_fusion(%20) /* ty=Tensor[(1, 32, 32, 32), int8] */;
%22 = cast(%21, dtype="float32") /* ty=Tensor[(1, 32, 32, 32), float32] */;
multiply(%22, 0.0625f /* ty=float32 */) /* ty=Tensor[(1, 32, 32, 32), float32] */
}