YOLOv1#
以下是关于 YOLOv1 的详细阐述,结合其核心原理、网络设计及局限性等关键点进行结构化分析:
相反,我们将对象检测定义为
网络架构设计#
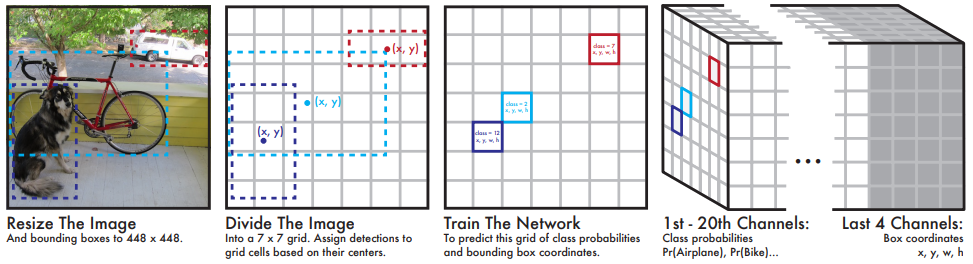
图 17 YOLOv1 将检测建模为
YOLOv1 将输入图像划分为
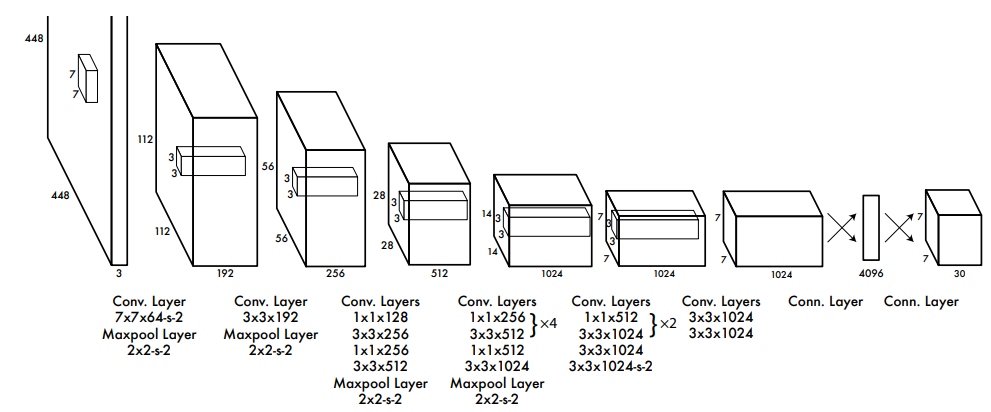
图 18 检测网络有 24 个卷积层(提取特征),后跟 2 个全连接层(预测输出概率和坐标)。该网络使用跨步(strided)卷积层来对特征空间进行下采样,而不是最大池化层。交替使用
网络的最终输出是
最后一层预测类概率和边界框坐标。通过图像宽度和高度对边界框的宽度和高度进行标准化,使它们介于
损失函数设计#
以下是YOLOv1损失函数设计的详细解析,结合其核心原理与实现逻辑整理:
YOLOv1的损失函数由三部分构成,旨在平衡目标定位、置信度预测和分类精度:
坐标定位误差(Localization Loss)
优化边界框中心点坐标置信度误差(Confidence Loss)
区分预测框是否包含物体,同时衡量预测框与真实框的交并比(IoU)。分类误差(Classification Loss)
预测网格内物体的类别概率分布。
坐标定位误差#
中心点坐标误差:
$宽高误差(平方根处理):
$关键设计:对宽高取平方根,缓解大目标与小目标的尺度敏感性问题(相同绝对误差对小目标影响更大)。
权重:
置信度误差
含物体的置信度误差:
$不含物体的置信度误差:
$权重平衡:
分类误差
公式:
$仅对有物体的网格计算,预测20类(VOC数据集)的概率分布。
局限性:采用均方误差而非交叉熵,分类效果弱于现代方法。
后续改进方向 YOLOv2及后续版本针对上述问题优化:
引入锚框(Anchor Boxes)提升定位精度。
分类损失改用交叉熵。
多尺度预测解决小目标检测问题。
训练策略#
预训练与微调:
在 ImageNet 上预训练前 20 层(输入 224×224),后 4 层卷积和全连接层随机初始化;
微调阶段将输入分辨率提升至 448×448,增强细节感知。
数据增强:采用随机缩放、平移和调整曝光度,提升模型泛化能力。
局限性#
YOLOv1 对边界框预测施加了很强的空间限制,因为每个网格单元格只预测一个框。此空间约束限制了模型可以预测的附近对象的数量。如果两个对象落入同一个单元格,模型只能预测其中一个。模型难以处理成群出现的小物体,例如鸟群。由于模型学习从数据中预测边界框,因此它很难推广到具有新的或不寻常的纵横比或配置的对象。模型还使用相对粗略的特征来预测边界框,因为架构从输入图像中有多个下采样层。最后,当我们训练近似检测性能的损失函数时,我们的损失函数在小边界框和大边界框中处理错误的方式相同。大盒子中的小错误通常是良性的,但小盒子中的小错误对 IOU 的影响要大得多。我们的主要错误来源是不正确的局部化。