DIV2K 数据#
DIV2K 数据集是广泛用于图像超分辨率(Super-Resolution, SR)研究的高质量图像数据集。它由2K分辨率的图像组成,提供了高分辨率(HR)图像和相应的低分辨率(LR)图像,用于训练和测试超分辨率算法。
数据集概述#
DIV2K 数据集分为以下几部分:
训练数据:从 800 张高清晰度的高分辨率图像开始,获取相应的低分辨率图像,并为2倍、3倍和4倍缩小因子提供高分辨率和低分辨率图像。
验证数据:使用100张高清晰度的高分辨率图像来生成对应的低分辨率图像,低分辨率图像从挑战开始时就提供,目的是让参与者能够从验证服务器获得在线反馈;高分辨率图像将在挑战的最后阶段开始时发布。
测试数据:使用100张多样化的图像来生成对应的低分辨率图像;参与者将在最终评估阶段开始时收到低分辨率图像,结果将在挑战结束后以及获胜者确定后公布。
数据结构#
DIV2K 数据集具有以下结构:
1000 张 2K 分辨率的图像,分为:800 张用于训练,100 张用于验证,100 张用于测试。
对于每个挑战赛道(包括 1. 三次插值或2. 未知降级操作),拥有:
高分辨率图像:0001.png, 0002.png, …, 1000.png
缩放后的图像:
YYYYx2.png为缩放因子x2;其中YYYY是图像IDYYYYx3.png为缩放因子x3;其中YYYY是图像IDYYYYx4.png为缩放因子x4;其中YYYY是图像ID
DIV2K 数据集的文件夹结构如下:
DIV2K/DIV2K_train_HR/–0001.png,0002.png, …,0800.png训练高分辨率图像(提供给参赛者)DIV2K/DIV2K_train_LR_bicubic/– 使用 Matlab imresize 函数和默认设置(双三次插值)获得的相应低分辨率图像DIV2K/DIV2K_train_LR_bicubic/X2/–0001x2.png,0002x2.png, …,0800x2.png训练低分辨率图像,下采样因子x2DIV2K/DIV2K_train_LR_bicubic/X3/–0001x3.png,0002x3.png, …,0800x3.png训练低分辨率图像,下采样因子x3DIV2K/DIV2K_train_LR_bicubic/X4/–0001x4.png,0002x4.png, …,0800x4.png训练低分辨率图像,下采样因子x4
DIV2K/DIV2K_train_LR_unknown/– 使用隐藏的退化算子获得的相应低分辨率图像,对参赛者未知DIV2K/DIV2K_train_LR_unknown/X2/–0001x2.png,0002x2.png, …,0800x2.png训练低分辨率图像,下采样因子x2DIV2K/DIV2K_train_LR_unknown/X3/–0001x3.png,0002x3.png, …,0800x3.png训练低分辨率图像,下采样因子x3DIV2K/DIV2K_train_LR_unknown/X4/–0001x4.png,0002x4.png, …,0800x4.png训练低分辨率图像,下采样因子x4
DIV2K/DIV2K_valid_HR/–0801.png,0802.png, …,0900.png验证高分辨率图像(将在最终评估阶段开始时提供给参赛者)DIV2K/DIV2K_valid_LR_bicubic/– 使用 Matlab imresize 函数和默认设置(双三次插值)获得的相应低分辨率图像DIV2K/DIV2K_valid_LR_bicubic/X2/– 0801x2.png, 0802x2.png, …, 0900x2.png 验证低分辨率图像,下采样因子x2DIV2K/DIV2K_valid_LR_bicubic/X3/– 0801x3.png, 0802x3.png, …, 0900x3.png 验证低分辨率图像,下采样因子x3DIV2K/DIV2K_valid_LR_bicubic/X4/– 0801x4.png, 0802x4.png, …, 0900x4.png 验证低分辨率图像,下采样因子x4
DIV2K/DIV2K_valid_LR_unknown/– 使用隐藏的退化算子获得的相应低分辨率图像,对参赛者未知DIV2K/DIV2K_valid_LR_unknown/X2/– 0801x2.png, 0802x2.png, …, 0900x2.png 验证低分辨率图像,下采样因子x2DIV2K/DIV2K_valid_LR_unknown/X3/– 0801x3.png, 0802x3.png, …, 0900x3.png 验证低分辨率图像,下采样因子x3DIV2K/DIV2K_valid_LR_unknown/X4/– 0801x4.png, 0802x4.png, …, 0900x4.png 验证低分辨率图像,下采样因子x4
DIV2K/DIV2K_test_HR/– 0901.png, 0902.png, …, 1000.png 测试高分辨率图像(不提供给参赛者,用于最终评估和排名)DIV2K/DIV2K_test_LR_bicubic/– 使用Matlab imresize函数和默认设置(双三次插值)获得的相应低分辨率图像DIV2K/DIV2K_test_LR_bicubic/X2/– 0901x2.png, 0902x2.png, …, 1000x2.png 测试低分辨率图像,下采样因子x2DIV2K/DIV2K_test_LR_bicubic/X3/– 0901x3.png, 0902x3.png, …, 1000x3.png 测试低分辨率图像,下采样因子x3DIV2K/DIV2K_test_LR_bicubic/X4/– 0901x4.png, 0902x4.png, …, 1000x4.png 测试低分辨率图像,下采样因子x4
DIV2K/DIV2K_test_LR_unknown/– 使用隐藏的退化算子获得的相应低分辨率图像,对参赛者未知DIV2K/DIV2K_test_LR_unknown/X2/– 0901x2.png, 0902x2.png, …, 1000x2.png 测试低分辨率图像,下采样因子x2DIV2K/DIV2K_test_LR_unknown/X3/– 0901x3.png, 0902x3.png, …, 1000x3.png 测试低分辨率图像,下采样因子x3DIV2K/DIV2K_test_LR_unknown/X4/– 0901x4.png, 0902x4.png, …, 1000x4.png 测试低分辨率图像,下采样因子x4
数据加载#
%matplotlib inline
import matplotlib.pyplot as plt
# 关闭交互模式
plt.ioff()
from pathlib import Path
from set_env import temp_dir
(temp_dir/"output/datasets").mkdir(exist_ok=True)
项目根目录:/media/pc/data/lxw/ai/torch-book
列出下载后是数据集:
data_dir = "/media/pc/data/lxw/data/SR/DIV2K"
data_dir = Path(data_dir)
for item in data_dir.iterdir():
if item.is_file() and item.suffix == '.zip':
print(item.name)
Show code cell output
DIV2K_valid_LR_x8.zip
DIV2K_train_LR_bicubic_X2.zip
DIV2K_train_LR_bicubic_X3.zip
DIV2K_train_LR_bicubic_X4.zip
DIV2K_train_LR_difficult.zip
DIV2K_train_LR_mild.zip
DIV2K_train_LR_unknown_X2.zip
DIV2K_train_LR_unknown_X4.zip
DIV2K_train_LR_wild.zip
DIV2K_train_LR_x8.zip
DIV2K_valid_LR_bicubic_X2.zip
DIV2K_valid_LR_bicubic_X3.zip
DIV2K_valid_LR_bicubic_X4.zip
DIV2K_valid_LR_difficult.zip
DIV2K_valid_LR_mild.zip
DIV2K_valid_LR_unknown_X2.zip
DIV2K_valid_LR_unknown_X3.zip
DIV2K_valid_LR_unknown_X4.zip
DIV2K_valid_LR_wild.zip
DIV2K_train_LR_unknown_X3.zip
DIV2K_train_HR.zip
DIV2K_valid_HR.zip
加载一些包:
import io
from PIL import Image
from torch_book.data.cv.zipfile import LoadBufferFromZipFile
LoadBufferFromZipFile 直接从 .zip 文件中加载图片 buffer 列表:
dataset = LoadBufferFromZipFile(data_dir/"DIV2K_train_HR.zip")
filenames 存储的图片名称列表(已经排序)。
dataset.filenames[:5]
['DIV2K_train_HR/0001.png',
'DIV2K_train_HR/0002.png',
'DIV2K_train_HR/0003.png',
'DIV2K_train_HR/0004.png',
'DIV2K_train_HR/0005.png']
样本数量:
len(dataset)
800
给定文件名称,可以获取图片二进制数据:
buffer = dataset('DIV2K_train_HR/0001.png')
查看图片的内容:
im = Image.open(io.BytesIO(buffer))
im.resize((224, 224))

制作训练/验证数据集#
由于 SR 需要 (LR, HR) 数据对进行模型训练,因此需要对数据进行一些预处理
from dataclasses import dataclass
from typing import Callable
from torch.utils.data.dataset import Dataset
from torchvision import tv_tensors
from torch_book.datasets.cv.div2k import PairedDIV2K
@dataclass
class PairedDataset(PairedDIV2K, Dataset):
transform: Callable | None = None
def __getitem__(self, index: int) -> list[tv_tensors.Image, tv_tensors.Image]:
"""加载(LR, HR)图片对
Args:
index: 图片的索引
Returns:
buffer: 图片的二进制内容
"""
with Image.open(io.BytesIO(self.lr_dataset[index])) as im:
lr = tv_tensors.Image(im)
with Image.open(io.BytesIO(self.hr_dataset[index])) as im:
hr = tv_tensors.Image(im)
if self.transform is not None:
lr, hr = self.transform(lr, hr)
return lr, hr
# 加载图片对
scale = 4 # 放大倍数, 2, 3, 4
dataset = PairedDataset(
scale,
data_dir/"DIV2K_train_HR.zip",
data_dir/f"DIV2K_train_LR_bicubic_X{scale}.zip"
)
dataset
PairedDataset(scale=4, HR_path=PosixPath('/media/pc/data/lxw/data/SR/DIV2K/DIV2K_train_HR.zip'), LR_path=PosixPath('/media/pc/data/lxw/data/SR/DIV2K/DIV2K_train_LR_bicubic_X4.zip'), transform=None)
图片对数量:
len(dataset)
800
查看图片对 shape 信息:
lr, hr = dataset[0]
lr.shape, hr.shape
(torch.Size([3, 351, 510]), torch.Size([3, 1404, 2040]))
裁剪子图像#
备注
在超分辨率(Super-Resolution, SR)算法中,裁剪子图像 的作用主要是为了提高计算效率、减少内存占用以及处理大尺寸图像时可能遇到的限制。具体来说,这个操作有以下几个主要作用:
提高计算效率
超分辨率算法通常需要对图像进行多次卷积操作,处理大尺寸图像时,计算量会显著增加。将大图像裁剪成多个较小的子图像(subimages)可以减少每次处理的计算量,从而提高整体计算效率。
对于深度学习模型,尤其是基于卷积神经网络(CNN)的超分算法,处理小尺寸的子图像可以减少模型的计算负担,加快训练或推理速度。
减少内存占用
大尺寸图像在内存中的存储和处理会占用大量资源,尤其是在使用GPU进行加速时,显存有限。将图像裁剪成多个子图像可以有效减少内存占用,使得算法能够在资源受限的硬件上运行。
对于一些显存较小的设备(如笔记本电脑或嵌入式设备),裁剪图像到子图像是一个常见的优化策略。
处理大尺寸图像的限制
某些超分算法或深度学习框架对输入图像的尺寸有一定的限制(例如,某些模型可能要求输入图像的尺寸是2的幂次方,或者不能超过某个最大尺寸)。通过裁剪图像到子图像,可以避免这些限制,确保算法能够正常运行。
避免边缘效应
在超分辨率任务中,图像的边缘区域可能会因为卷积操作而产生不理想的处理效果(例如,边缘模糊或伪影)。通过将图像裁剪成多个子图像,可以避免单张大图像的边缘区域受到过多的影响。
此外,裁剪后的子图像可以进行重叠(overlap)处理,以确保相邻子图像之间的过渡更加平滑,避免明显的边界效应。
数据增强
在训练阶段,裁剪图像到子图像可以作为一种数据增强的手段。通过随机裁剪或选择不同的子图像区域,可以增加训练数据的多样性,从而提高模型的泛化能力。
处理局部细节
超分辨率任务中,图像的不同区域可能具有不同的细节复杂度。通过裁剪图像到子图像,可以更精细地处理图像的局部区域,尤其是那些细节丰富的区域,从而提高整体的超分辨率效果。
通过这些操作,超分算法可以在有限的计算资源下更高效地处理图像,并获得更好的超分辨率效果。
from pathlib import Path
def create_dataset(root, scale, transform):
root = Path(root)
# 将训练集和验证集合并
_trainset = PairedDataset(
scale,
root/"DIV2K_train_HR.zip",
root/f"DIV2K_train_LR_bicubic_X{scale}.zip",
transform=transform
)
_valset = PairedDataset(
scale,
root/"DIV2K_valid_HR.zip",
root/f"DIV2K_valid_LR_bicubic_X{scale}.zip",
transform=transform
)
return _trainset + _valset
from torch_book.data.cv.grid import PairedGrid, GridConfig
# 加载图片对
scale = 4 # 放大倍数, 2, 3, 4
config = GridConfig(
crop_size = 480, # HR 的裁剪尺寸,这个尺寸通常是预先设定的
step = 240, # 指在 HR 图像进行某种处理时,每次移动或采样的步长
thresh_size = 0, # HR 图像处理中,用于判断或筛选某些特征或对象的尺寸阈值
)
transform = PairedGrid(scale, config)
dataset = create_dataset(data_dir, scale, transform)
lr, hr = dataset[0]
lr.shape, hr.shape
(torch.Size([5, 8, 3, 120, 120]), torch.Size([5, 8, 3, 480, 480]))
可视化:
import torch
from torch_book.data.cv.plot import GridFrame
lr, hr = dataset[0]
with torch.no_grad():
data = lr.flatten().permute(0, 2, 3, 1)
canvas = GridFrame(*lr.shape[:2], 0.7)
canvas(data)
plt.close()
canvas.figure
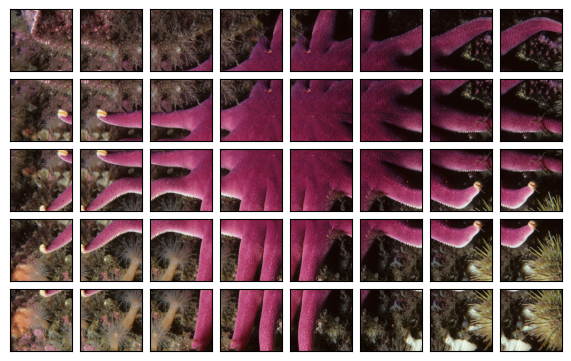
可以将 Grid 数据展平:
from torchvision.transforms import v2
from torch_book.data.cv.grid import PairedGrid, GridConfig, FlattenPairedGrid
# 加载图片对
scale = 4 # 放大倍数, 2, 3, 4
config = GridConfig(
crop_size = 480, # HR 的裁剪尺寸,这个尺寸通常是预先设定的
step = 240, # 指在 HR 图像进行某种处理时,每次移动或采样的步长
thresh_size = 0, # HR 图像处理中,用于判断或筛选某些特征或对象的尺寸阈值
)
transform = v2.Compose([PairedGrid(scale, config), FlattenPairedGrid()])
dataset = create_dataset(data_dir, scale, transform)
lr, hr = dataset[0]
lr.shape, hr.shape
(torch.Size([40, 3, 120, 120]), torch.Size([40, 3, 480, 480]))
PairedRandomCrop#
PairedRandomCrop 是一种用于图像数据增强的技术,通常用于生成图像对(例如高分辨率图像和低分辨率图像)的训练数据。PairedRandomCrop 的主要目的是确保在数据增强过程中,高分辨率图像和低分辨率图像的裁剪区域保持一致,从而保证训练数据的配对关系。
实现原理#
PairedRandomCrop 的实现原理如下:
随机选择裁剪区域:在高分辨率图像上随机选择一个裁剪区域。
计算低分辨率图像的裁剪区域:根据高分辨率图像的裁剪区域和下采样比例,计算低分辨率图像的对应裁剪区域。
裁剪图像:分别在高分辨率图像和低分辨率图像上裁剪出相同区域的子图像。
from torchvision.transforms import v2
from torch_book.data.cv.grid import PairedGrid, GridConfig, PairedRandomCrop
from torch_book.data.cv.plot import CompareGridFrame
# 加载图片对
config = GridConfig(
crop_size = 480, # HR 的裁剪尺寸,这个尺寸通常是预先设定的
step = 240, # 指在 HR 图像进行某种处理时,每次移动或采样的步长
thresh_size = 0, # HR 图像处理中,用于判断或筛选某些特征或对象的尺寸阈值
)
transform = v2.Compose([
PairedGrid(scale, config),
PairedRandomCrop(scale=scale, gt_patch_size=128)
])
dataset = create_dataset(data_dir, scale, transform)
lr, hr = dataset[14]
print(f"lr.shape, hr.shape: {lr.shape, hr.shape}")
with torch.no_grad():
lr = lr.flatten()
hr = hr.flatten()
canvas = CompareGridFrame(5, 8, 0.8)
left_axes, right_axes = canvas(lr.permute(0, 2, 3, 1), hr.permute(0, 2, 3, 1))
left_axes[4].set_title("LR")
right_axes[4].set_title("HR")
canvas.figure.suptitle("LQ")
plt.close()
canvas.figure
lr.shape, hr.shape: (torch.Size([5, 8, 3, 32, 32]), torch.Size([5, 8, 3, 128, 128]))

lr, hr = dataset[14]
print(f"lr.shape, hr.shape: {lr.shape, hr.shape}")
with torch.no_grad():
lr = lr.flatten()
hr = hr.flatten()
canvas = CompareGridFrame(5, 8, 0.7)
left_axes, right_axes = canvas(lr.permute(0, 2, 3, 1), hr.permute(0, 2, 3, 1))
left_axes[4].set_title("LR")
right_axes[4].set_title("HR")
canvas.figure.suptitle("LQ")
plt.close()
canvas.figure
lr.shape, hr.shape: (torch.Size([5, 8, 3, 32, 32]), torch.Size([5, 8, 3, 128, 128]))

打乱 Grid 中图像块的顺序:
lr, hr = dataset[14]
print(f"lr.shape, hr.shape: {lr.shape, hr.shape}")
with torch.no_grad():
indexes = lr.randmeshgrid()
lr = lr.shuffle(indexes).flatten()
hr = hr.shuffle(indexes).flatten()
canvas = CompareGridFrame(5, 8, 0.7)
left_axes, right_axes = canvas(lr.permute(0, 2, 3, 1), hr.permute(0, 2, 3, 1))
left_axes[4].set_title("LR")
right_axes[4].set_title("HR")
canvas.figure.suptitle("LQ")
plt.close()
canvas.figure
lr.shape, hr.shape: (torch.Size([5, 8, 3, 32, 32]), torch.Size([5, 8, 3, 128, 128]))

创建 Grid 数据加载器#
创建数据加载器:
from torch.utils.data import DataLoader
from torch_book.data.cv.grid import Grid
class GridLoader(DataLoader):
def __init__(self, dataset, *args, **kwargs):
super().__init__(dataset, batch_size=1, *args, **kwargs)
def __iter__(self):
# 自定义迭代逻辑
for lr, hr in super().__iter__():
lr = lr[0].as_subclass(Grid)
hr = hr[0].as_subclass(Grid)
yield lr, hr
# 使用自定义 DataLoader
loader = GridLoader(dataset, shuffle=True)
for index, batch in enumerate(loader):
if index == 10:
break
print(batch[0].shape, batch[1].shape)
batch[0].flatten().unflatten().shape
torch.Size([8, 4, 3, 32, 32]) torch.Size([8, 4, 3, 128, 128])
torch.Size([7, 8, 3, 32, 32]) torch.Size([7, 8, 3, 128, 128])
torch.Size([4, 8, 3, 32, 32]) torch.Size([4, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32]) torch.Size([5, 8, 3, 128, 128])
torch.Size([8, 6, 3, 32, 32]) torch.Size([8, 6, 3, 128, 128])
torch.Size([5, 8, 3, 32, 32])