分块矩阵乘法#
原作者: Thierry Moreau
本教程概述了如何在 VTA 设计中使用 TVM 有效地映射矩阵乘法。建议先学习 简单的矩阵乘法 教程。
在本教程中,将演示 TVM 调度优化,将大型神经网络算子分解为较小的块,以在有限的硬件加速器资源内实现计算。
RPC 设置#
首先编程 Pynq 的 FPGA 并构建它的 RPC 运行时。
import os
import tvm
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
# Load VTA parameters from the 3rdparty/vta-hw/config/vta_config.json file
env = vta.get_env()
# We read the Pynq RPC host IP address and port number from the OS environment
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# We configure both the bitstream and the runtime system on the Pynq
# to match the VTA configuration specified by the vta_config.json file.
if env.TARGET == "pynq":
# Make sure that TVM was compiled with RPC=1
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# Reconfigure the JIT runtime
vta.reconfig_runtime(remote)
# Program the FPGA with a pre-compiled VTA bitstream.
# You can program the FPGA with your own custom bitstream
# by passing the path to the bitstream file instead of None.
vta.program_fpga(remote, bitstream=None)
# In simulation mode, host the RPC server locally.
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
声明计算#
作为第一步,需要描述矩阵乘法的计算。将矩阵乘法定义为全连接层中的计算,由其 batch size、输入通道和输出通道定义。它们必须是 VTA 张量形状的整数倍:BATCH、BLOCK_IN 和 BLOCK_OUT。
在矩阵乘法中添加额外的算子,这些算子对输出进行了移位(shifting)和剪切(clipping),以模拟定点矩阵乘法,然后是修正的线性激活。将全连通层的 TVM 数据流图描述如下:
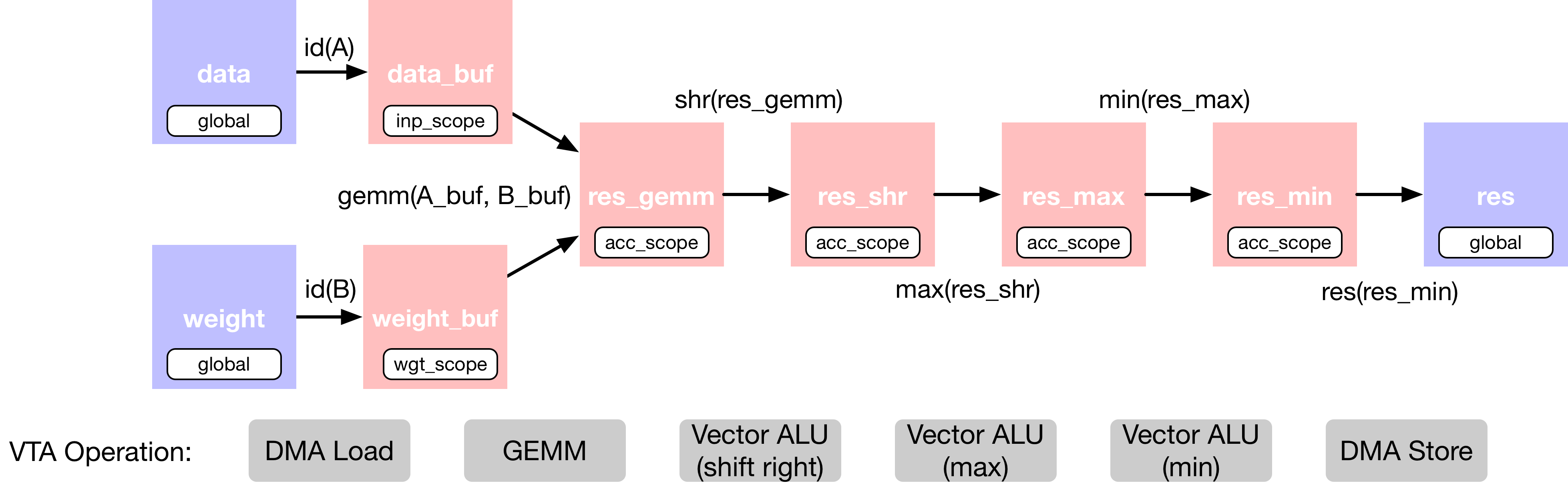
此计算被故意设置得太大,以至于不能一次全部放入 VTA 的 on-chip buffer。因此,在调度阶段,将依靠计算分块策略将计算分解为可管理的块。
# 全连接层 1024 x 1024
batch_size = 1
in_channels = 1024
out_channels = 1024
num_ops = in_channels * out_channels * batch_size * 2
assert batch_size % env.BATCH == 0
assert in_channels % env.BLOCK_IN == 0
assert out_channels % env.BLOCK_OUT == 0
# 推导出平铺的张量形状
data_shape = (
batch_size // env.BATCH,
in_channels // env.BLOCK_IN,
env.BATCH, env.BLOCK_IN
)
weight_shape = (
out_channels // env.BLOCK_OUT,
in_channels // env.BLOCK_IN,
env.BLOCK_OUT,
env.BLOCK_IN,
)
output_shape = (
batch_size // env.BATCH,
out_channels // env.BLOCK_OUT,
env.BATCH, env.BLOCK_OUT
)
# Reduction axes
ic = te.reduce_axis((0, in_channels // env.BLOCK_IN), name="ic")
ic_tns = te.reduce_axis((0, env.BLOCK_IN), name="ic_tns")
# Input placeholder tensors
data = te.placeholder(data_shape, name="data", dtype=env.inp_dtype)
weight = te.placeholder(weight_shape, name="weight", dtype=env.wgt_dtype)
# Copy buffers
data_buf = te.compute(data_shape, lambda *i: data(*i), "data_buf")
weight_buf = te.compute(weight_shape, lambda *i: weight(*i), "weight_buf")
# 声明矩阵乘法计算
res_gemm = te.compute(
output_shape,
lambda bo, co, bi, ci: te.sum(
data_buf[bo, ic, bi, ic_tns].astype(env.acc_dtype)
* weight_buf[co, ic, ci, ic_tns].astype(env.acc_dtype),
axis=[ic, ic_tns],
),
name="res_gem",
)
# 为定点归一化(fix-point normalization)添加 shift stage
res_shr = te.compute(output_shape, lambda *i: res_gemm(*i) >> env.INP_WIDTH, name="res_shr")
# 将值裁剪到 (0, input max value)
inp_max = (1 << (env.INP_WIDTH - 1)) - 1
res_max = te.compute(output_shape, lambda *i: tvm.te.max(res_shr(*i), 0), "res_max")
res_min = te.compute(output_shape, lambda *i: tvm.te.min(res_max(*i), inp_max), "res_min")
# 在返回结果之前,对输入数据类型应用类型转换
res = te.compute(output_shape, lambda *i: res_min(*i).astype(env.inp_dtype), name="res")
调度计算#
查看一组必要的调度变换,以有效的方式将矩阵乘法映射到 VTA。这些包括:
分块计算(Computation blocking)
Lowering 到 VTA 硬件 intrinsics
# 创建 TVM 调度
s = te.create_schedule(res.op)
# 查看默认调度
tvm.lower(s, [data, weight, res], simple_mode=True).show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(
data: T.Buffer((1, 64, 1, 16), "int8"),
weight: T.Buffer((64, 64, 16, 16), "int8"),
res: T.Buffer((1, 64, 1, 16), "int8"),
):
T.func_attr(
{
"from_legacy_te_schedule": T.bool(True),
"global_symbol": "main",
"tir.noalias": T.bool(True),
}
)
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([1024], "int32", "global")
data_buf_1 = T.Buffer((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_1 = T.Buffer((1024,), "int8", data=data.data)
data_buf_1[cse_var_1] = data_1[cse_var_1]
weight_buf_1 = T.Buffer((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_1 = T.Buffer((1048576,), "int8", data=weight.data)
weight_buf_1[cse_var_2] = weight_1[cse_var_2]
res_gem_1 = T.Buffer((1024,), "int32", data=res_gem)
for co, ci in T.grid(64, 16):
res_gem_1[co * 16 + ci] = 0
for ic, ic_tns in T.grid(64, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast(
"int32", data_buf_1[ic * 16 + ic_tns]
) * T.Cast(
"int32", weight_buf_1[co * 16384 + ic * 256 + ci * 16 + ic_tns]
)
res_gem_2 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.Buffer((1024,), "int32", data=res_gem)
for i1, i3 in T.grid(64, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1, i3 in T.grid(64, 16):
cse_var_7: T.int32 = i1 * 16 + i3
res_1 = T.Buffer((1024,), "int8", data=res.data)
res_1[cse_var_7] = T.Cast("int8", res_gem_4[cse_var_7])
分块计算#
在默认情况下,矩阵乘法对于激活或权重来说太大了,无法一次性适应 VTA 的 on-chip buffer。将 (1, 1024)×(1024, 1024) 矩阵乘法分成更小的 (1, 256) × (256, 256) 矩阵乘法,这样中间张量就可以装进加速器的 on-chip SRAM 中。这种方法类似于将分块技术应用于 CPU 和 GPU,以提高缓存命中率(cache hit rate)。
沿着每个轴执行分块(batch 轴不受影响,因为正在执行单 batch 推理)。也保持最内侧的 tensorization 轴不变,以便 TVM 能够进行模式匹配的 tensorization。在下面的图表中展示了分块在计算调度上的结果:

循环分割(splitting)和重新排序(reordering)后的代码等价于下面的伪代码。忽略 batch 轴,因为在这个例子中只执行单 batch 推断:
for (int oc_out = 0; oc_out < 4; ++oc_out) {
// Initialization loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][j] = 0;
}
}
for (int ic_out = 0; ic_out < 4; ++ic_out) {
// Block loop
for (int oc_inn = 0; oc_inn < 16; ++oc_inn) {
for (int ic_inn = 0; ic_inn < 16; ++ic_inn) {
// Tensorization loop
for (int oc_tns = 0; oc_tns < 16; ++oc_tns) {
for (int ic_tns = 0; ic_tns < 16; ++ic_tns) {
int i = (ic_out * 16 + ic_inn) * 16 + ic_tns;
int j = (oc_out * 16 + oc_inn) * 16 + oc_tns;
C[0][i] = C[0][i] + A[0][i] * B[j][i];
}
}
}
}
}
}
}
# Let's define tiling sizes (expressed in multiples of VTA tensor shape size)
b_block = 1 // env.BATCH
i_block = 256 // env.BLOCK_IN
o_block = 256 // env.BLOCK_OUT
# Tile the output tensor along the batch and output channel dimensions
# (since by default we are doing single batch inference, the split along
# the batch dimension has no effect)
b, oc, b_tns, oc_tns = s[res].op.axis
b_out, b_inn = s[res].split(b, b_block)
oc_out, oc_inn = s[res].split(oc, o_block)
s[res].reorder(b_out, oc_out, b_inn, oc_inn)
# Move intermediate computation into each output compute tile
s[res_gemm].compute_at(s[res], oc_out)
s[res_shr].compute_at(s[res], oc_out)
s[res_max].compute_at(s[res], oc_out)
s[res_min].compute_at(s[res], oc_out)
# Apply additional loop split along reduction axis (input channel)
b_inn, oc_inn, b_tns, oc_tns = s[res_gemm].op.axis
ic_out, ic_inn = s[res_gemm].split(ic, i_block)
# Reorder axes. We move the ic_out axis all the way out of the GEMM
# loop to block along the reduction axis
s[res_gemm].reorder(ic_out, b_inn, oc_inn, ic_inn, b_tns, oc_tns, ic_tns)
# Let's look at the current TVM schedule after blocking
tvm.lower(s, [data, weight, res], simple_mode=True).show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(
data: T.Buffer((1, 64, 1, 16), "int8"),
weight: T.Buffer((64, 64, 16, 16), "int8"),
res: T.Buffer((1, 64, 1, 16), "int8"),
):
T.func_attr(
{
"from_legacy_te_schedule": T.bool(True),
"global_symbol": "main",
"tir.noalias": T.bool(True),
}
)
data_buf = T.allocate([1024], "int8", "global")
weight_buf = T.allocate([1048576], "int8", "global")
res_gem = T.allocate([256], "int32", "global")
data_buf_1 = T.Buffer((1024,), "int8", data=data_buf)
for i1, i3 in T.grid(64, 16):
cse_var_1: T.int32 = i1 * 16 + i3
data_1 = T.Buffer((1024,), "int8", data=data.data)
data_buf_1[cse_var_1] = data_1[cse_var_1]
weight_buf_1 = T.Buffer((1048576,), "int8", data=weight_buf)
for i0, i1, i2, i3 in T.grid(64, 64, 16, 16):
cse_var_2: T.int32 = i0 * 16384 + i1 * 256 + i2 * 16 + i3
weight_1 = T.Buffer((1048576,), "int8", data=weight.data)
weight_buf_1[cse_var_2] = weight_1[cse_var_2]
for i1_outer in range(4):
res_gem_1 = T.Buffer((256,), "int32", data=res_gem)
for co_init, ci_init in T.grid(16, 16):
res_gem_1[co_init * 16 + ci_init] = 0
for ic_outer, co, ic_inner, ci, ic_tns in T.grid(4, 16, 16, 16, 16):
cse_var_3: T.int32 = co * 16 + ci
res_gem_1[cse_var_3] = res_gem_1[cse_var_3] + T.Cast(
"int32", data_buf_1[ic_outer * 256 + ic_inner * 16 + ic_tns]
) * T.Cast(
"int32",
weight_buf_1[
i1_outer * 262144
+ co * 16384
+ ic_outer * 4096
+ ic_inner * 256
+ ci * 16
+ ic_tns
],
)
res_gem_2 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_4: T.int32 = i1 * 16 + i3
res_gem_2[cse_var_4] = T.shift_right(res_gem_1[cse_var_4], 8)
res_gem_3 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_5: T.int32 = i1 * 16 + i3
res_gem_3[cse_var_5] = T.max(res_gem_2[cse_var_5], 0)
res_gem_4 = T.Buffer((256,), "int32", data=res_gem)
for i1, i3 in T.grid(16, 16):
cse_var_6: T.int32 = i1 * 16 + i3
res_gem_4[cse_var_6] = T.min(res_gem_3[cse_var_6], 127)
for i1_inner, i3 in T.grid(16, 16):
cse_var_7: T.int32 = i1_inner * 16
res_1 = T.Buffer((1024,), "int8", data=res.data)
res_1[i1_outer * 256 + cse_var_7 + i3] = T.Cast(
"int8", res_gem_4[cse_var_7 + i3]
)
lowering 复制到 DMA 传输#
接下来,将 buffer 作用域设置为相应的 on-chip VTA SRAM buffer。将 load 循环移动到矩阵乘法计算循环中,以使它们适合于 on-chip SRAM buffer。最后,用 DMA 复制实用程序对 load/store 循环外轴进行注解,以在 VTA 上执行批量内存传输。
# Set scope of SRAM buffers
s[data_buf].set_scope(env.inp_scope)
s[weight_buf].set_scope(env.wgt_scope)
s[res_gemm].set_scope(env.acc_scope)
s[res_shr].set_scope(env.acc_scope)
s[res_min].set_scope(env.acc_scope)
s[res_max].set_scope(env.acc_scope)
# Block data and weight cache reads
s[data_buf].compute_at(s[res_gemm], ic_out)
s[weight_buf].compute_at(s[res_gemm], ic_out)
# Use DMA copy pragma on DRAM->SRAM operations
s[data_buf].pragma(s[data_buf].op.axis[0], env.dma_copy)
s[weight_buf].pragma(s[weight_buf].op.axis[0], env.dma_copy)
# Use DMA copy pragma on SRAM->DRAM operation
# (this implies that these copies should be performed along b_inn,
# or result axis 2)
s[res].pragma(s[res].op.axis[2], env.dma_copy)
Lowering 计算到 VTA Compute Intrinsics#
最后阶段是通过将矩阵乘法映射到张量 intrinsics,将 shift 映射到矢量 ALU,从而将计算循环 lowering 到 VTA 硬件 intrinsics。
# Apply tensorization over the batch tensor tile axis
s[res_gemm].tensorize(b_tns, env.gemm)
# Add an ALU pragma over the shift and clipping operations
s[res_shr].pragma(s[res_shr].op.axis[0], env.alu)
s[res_min].pragma(s[res_min].op.axis[0], env.alu)
s[res_max].pragma(s[res_max].op.axis[0], env.alu)
# Let's look at the final lowered TVM schedule after lowering memory
# loads/stores down to DMA copy intrinsics, and the computation down to
# VTA compute intrinsics.
vta.lower(s, [data, weight, res], simple_mode=True).show()
[18:17:17] /media/pc/data/lxw/ai/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.uop_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.command_handle
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_push
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_sync
[18:17:17] /media/pc/data/lxw/ai/tvm/src/script/printer/tir/expr.cc:246: Warning: No TScriptPrinterName attribute for tir.vta.coproc_dep_pop
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(
data: T.Buffer((1, 64, 1, 16), "int8"),
weight: T.Buffer((64, 64, 16, 16), "int8"),
res: T.Buffer((1, 64, 1, 16), "int8"),
):
T.func_attr(
{
"from_legacy_te_schedule": T.bool(True),
"global_symbol": "main",
"tir.noalias": T.bool(True),
}
)
T.tir.vta.coproc_dep_push(3, 2)
for i1_outer in range(4):
vta = T.int32()
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
T.tir.vta.coproc_dep_pop(3, 2)
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"),
"coproc_uop_scope",
"VTAPushGEMMOp",
):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 0)
T.tir.vta.uop_push(0, 1, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
for ic_outer in range(4):
cse_var_1: T.int32 = ic_outer * 16
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 1
):
T.tir.vta.coproc_dep_pop(2, 1)
T.call_extern(
"int32",
"VTALoadBuffer2D",
T.tvm_thread_context(T.tir.vta.command_handle()),
data.data,
cse_var_1,
16,
1,
16,
0,
0,
0,
0,
0,
2,
)
T.call_extern(
"int32",
"VTALoadBuffer2D",
T.tvm_thread_context(T.tir.vta.command_handle()),
weight.data,
i1_outer * 1024 + cse_var_1,
16,
16,
64,
0,
0,
0,
0,
0,
1,
)
T.tir.vta.coproc_dep_push(1, 2)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2)
T.tir.vta.coproc_dep_pop(1, 2)
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"),
"coproc_uop_scope",
"VTAPushGEMMOp",
):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 0, 16)
T.call_extern("int32", "VTAUopLoopBegin", 16, 0, 1, 1)
T.tir.vta.uop_push(0, 0, 0, 0, 0, 0, 0, 0)
T.call_extern("int32", "VTAUopLoopEnd")
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 1)
T.tir.vta.coproc_dep_pop(2, 1)
with T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 2):
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"),
"coproc_uop_scope",
"VTAPushALUOp",
):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 3, 1, 8)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"),
"coproc_uop_scope",
"VTAPushALUOp",
):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 1, 1, 0)
T.call_extern("int32", "VTAUopLoopEnd")
with T.attr(
T.iter_var(vta, None, "ThreadIndex", "vta"),
"coproc_uop_scope",
"VTAPushALUOp",
):
T.call_extern("int32", "VTAUopLoopBegin", 16, 1, 1, 0)
T.tir.vta.uop_push(1, 0, 0, 0, 0, 0, 1, 127)
T.call_extern("int32", "VTAUopLoopEnd")
T.tir.vta.coproc_dep_push(2, 3)
T.attr(T.iter_var(vta, None, "ThreadIndex", "vta"), "coproc_scope", 3)
T.tir.vta.coproc_dep_pop(2, 3)
for i1_inner in range(16):
T.call_extern(
"int32",
"VTAStoreBuffer2D",
T.tvm_thread_context(T.tir.vta.command_handle()),
i1_inner,
4,
res.data,
i1_outer * 16 + i1_inner,
1,
1,
1,
)
T.tir.vta.coproc_dep_push(3, 2)
T.tir.vta.coproc_sync()
T.tir.vta.coproc_dep_pop(3, 2)
TVM 计算和验证#
在指定调度之后,可以将其编译为 TVM 函数。保存模块,这样就可以通过 RPC 发送它。运行该函数并对 numpy 实现进行验证,以确保其正确性。
# Compile the TVM module
my_gemm = vta.build(
s, [data, weight, res], tvm.target.Target("ext_dev", host=env.target_host), name="my_gemm"
)
temp = utils.tempdir()
my_gemm.save(temp.relpath("gemm.o"))
remote.upload(temp.relpath("gemm.o"))
f = remote.load_module("gemm.o")
# Get the remote device context
ctx = remote.ext_dev(0)
# Initialize the data and weight arrays randomly in the int range of (-128, 128]
data_np = np.random.randint(-128, 128, size=(batch_size, in_channels)).astype(data.dtype)
weight_np = np.random.randint(-128, 128, size=(out_channels, in_channels)).astype(weight.dtype)
# Apply packing to the data and weight arrays from a 2D to a 4D packed layout
data_packed = data_np.reshape(
batch_size // env.BATCH, env.BATCH, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
weight_packed = weight_np.reshape(
out_channels // env.BLOCK_OUT, env.BLOCK_OUT, in_channels // env.BLOCK_IN, env.BLOCK_IN
).transpose((0, 2, 1, 3))
# Format the input/output arrays with tvm.nd.array to the DLPack standard
data_nd = tvm.nd.array(data_packed, ctx)
weight_nd = tvm.nd.array(weight_packed, ctx)
res_nd = tvm.nd.array(np.zeros(output_shape).astype(res.dtype), ctx)
# Clear stats
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
# Invoke the module to perform the computation
f(data_nd, weight_nd, res_nd)
# Verify against numpy implementation
res_ref = np.dot(data_np.astype(env.acc_dtype), weight_np.T.astype(env.acc_dtype))
res_ref = res_ref >> env.INP_WIDTH
res_ref = np.clip(res_ref, 0, inp_max)
res_ref = res_ref.astype(res.dtype)
res_ref = res_ref.reshape(
batch_size // env.BATCH, env.BATCH, out_channels // env.BLOCK_OUT, env.BLOCK_OUT
).transpose((0, 2, 1, 3))
np.testing.assert_equal(res_ref, res_nd.numpy())
# Print stats
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful blocked matrix multiply test!")
Execution statistics:
inp_load_nbytes : 4096
wgt_load_nbytes : 1048576
acc_load_nbytes : 0
uop_load_nbytes : 20
out_store_nbytes: 1024
gemm_counter : 4096
alu_counter : 192
Successful blocked matrix multiply test!
[18:17:19] /media/pc/data/lxw/ai/tvm/src/tir/transforms/arg_binder.cc:95: Warning: Trying to bind buffer to another one with lower alignment requirement required_alignment=256, provided_alignment=64
2023-04-20 18:17:19.789 INFO load_module /tmp/tmpqql8a5fm/gemm.o