部署到 Adreno™ GPU#
Authors: Daniil Barinov, Egor Churaev, Andrey Malyshev, Siva Rama Krishna
简介#
Adreno™ 是由高通开发的一系列图形处理器(GPU)半导体知识产权核心,用于其许多 SoC 中。
Adreno™ GPU 加速复杂几何图形的渲染,以提供高性能图形和丰富的用户体验,同时保持低功耗。
TVM 通过其原生 OpenCL 后端以及 OpenCLML 后端支持 Adreno™ GPU 上的深度学习加速。TVM 的原生 OpenCL 后端通过结合纹理内存使用和 Adreno™ 友好的布局进行了增强,使其更适合 Adreno™。OpenCLML 是高通发布的 SDK,为大多数深度学习算子提供内核加速库。
本指南旨在展示以下设计方面的内容:
OpenCL 后端增强#
TVM 的 OpenCL 后端经过增强,以利用 Adreno™ 的特定功能,例如:- 纹理内存使用。- Adreno™ 友好的激活布局。- 利用上述功能加速的全新调度。
Adreno™ 的优势之一是其对纹理的巧妙处理。目前,TVM 通过对 Adreno™ 的纹理支持从中受益。下图显示了 Adreno™ A5x 架构。
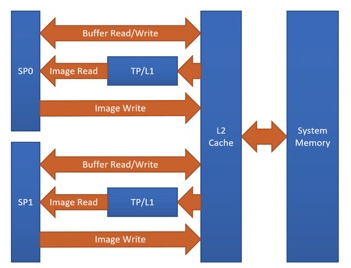
Fig. 1 High-level overview of the Adreno™ A5x architecture for OpenCL
source: OpenCL Optimization and Best Practices for Qualcomm Adreno™ GPUs
使用纹理的原因:
纹理处理器(Texture processor,简称 TP)具有专用的 L1 缓存,这是一个只读缓存,用于存储从二级(L2)缓存中获取的数据以进行纹理操作(主要原因)
图像边界的处理是内置的。
支持多种图像格式和数据类型组合,并支持自动格式转换
总体而言,与基于 OpenCL 缓冲区的解决方案相比,使用纹理可以显著提高性能。
通常,将目标指定为 target="opencl" 以生成基于常规 OpenCL 的目标,如下所示生成内核。
__kernel void tvmgen_default_fused_nn_conv2d_kernel0(__global float* restrict p0, __global double* restrict p1, __global float* restrict conv2d_nhwc) {
// body..
上述 OpenCL 内核定义中包含 __global float* 指针,这些指针本质上是 OpenCL 的 buffer 对象。
当通过将目标定义修改为 target="opencl -device=adreno" 来启用基于纹理的增强功能时,可以看到生成的核函数使用了基于纹理的 OpenCL 图像对象,如下所示。
__kernel void tvmgen_default_fused_nn_conv2d_kernel0(__write_only image2d_t pad_temp_global_texture, __read_only image2d_t p0) {
// body..
image2d_t 是 OpenCL 内置的类型,用于表示二维图像对象,并提供了多种附加功能。当使用 image2d_t 时,可以 一次性读取 4 个元素,这有助于更高效地利用硬件资源。
有关内核源代码的生成和检查的更多详细信息,请参阅 高级用法。
关于 OpenCLML#
OpenCLML 是由高通发布的 SDK,提供了加速的深度学习算子。这些算子作为标准 OpenCL 规范的扩展 cl_qcom_ml_ops 提供。更多详细信息,请参阅 使用 OpenCL ML SDK 加速您的模型。
OpenCLML 已作为 BYOC(自带代码生成) 解决方案集成到 TVM 中。OpenCLML 算子可以使用与原生 OpenCL 相同的上下文,并可以在相同的命令队列中排队。利用这一点,避免了在回退到原生 OpenCL 时的上下文切换开销。
适用于 Adreno™ 的 TVM#
本节提供了关于构建和部署模型到 Adreno™ 目标的各种方法的说明。Adreno™ 是远程目标设备,通过 ADB 连接与主机相连。在此部署编译后的模型需要在主机和目标设备上使用一些工具。
TVM 提供了简化的、用户友好的命令行工具,以及面向开发者的 Python API 接口,用于自动调优、构建和部署等各种步骤。
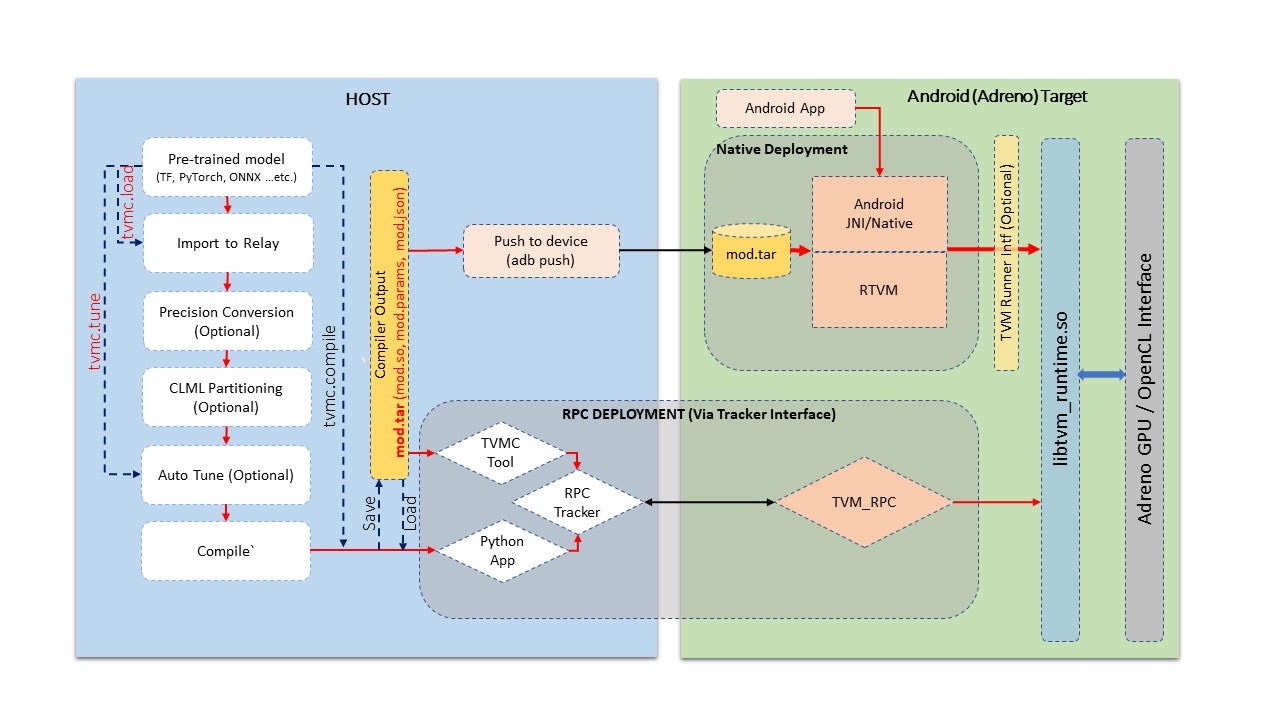
Fig.2 Build and Deployment pipeline on Adreno devices
上图展示了通用流程,涵盖了以下列出的各个阶段。
模型导入: 在此阶段,从 TensorFlow、PyTorch、ONNX 等知名框架中导入模型。此阶段将给定模型转换为 TVM 的 Relay 模块格式。或者,也可以通过使用 TVM 的算子库手动构建 Relay 模块。此处生成的 TVM 模块是图的与目标设备无关的表示形式。
自动调优: 在此阶段,针对特定目标设备对 TVM 生成的内核进行调优。自动调优过程需要目标设备的可用性,对于像 Android 设备上的 Adreno™ 这样的远程目标设备,使用 RPC 设置进行通信。本指南的后续部分将详细介绍 Android 设备的 RPC 设置。自动调优并不是模型编译的必要步骤,但它是为了从 TVM 生成的内核中获得最佳性能所必需的。
编译: 在此阶段,我们为特定目标设备编译模型。如果在上一阶段对模块进行了自动调优,TVM 编译过程将利用调优日志来生成性能最佳的内核。TVM 编译过程会生成一些文件,包括内核共享库、以 JSON 格式表示的图定义以及以 TVM 特定格式存储的参数二进制文件。
在目标设备上部署(或测试运行): 在此阶段,我们在目标设备上运行 TVM 编译的输出。可以通过使用 RPC 设置的 Python 环境进行部署,也可以使用 TVM 的原生工具进行部署,该工具是为 Android 交叉编译的原生二进制文件。在此阶段,我们可以在 Android 目标设备上运行编译后的模型,并对输出的正确性和性能方面进行单元测试。
应用程序集成: 此阶段主要是将 TVM 编译的模型集成到应用程序中。在这里,我们讨论如何从 Android(C++ 原生环境或通过 JNI)与 TVM 运行时进行交互,以设置输入并获取输出。
高级用法: 本节面向高级用户,涵盖查看生成的源代码、修改模块精度等内容。
本教程涵盖上述所有方面,具体内容将在以下部分中展开。
开发环境设置:自动#
TVM 提供了预定义的 Docker 容器环境,其中包含了所有快速入门的必备条件。您也可以参考 手动环境设置 以获得对依赖项的更多控制。
对于 Docker 设置,唯一的先决条件就是主机上需具备 Docker 工具的可用性。
以下命令可以构建用于 Adreno 的 Docker 镜像。
./docker/build.sh ci_adreno
docker tag tvm.ci_adreno ci_adreno
现在可以通过以下命令同时构建主机和目标设备的实用工具。
./tests/scripts/ci.py adreno -i
要使用 OpenCLML SDK 构建 TVM,需要在构建时导出 OpenCLML SDK,如下所示。
export ADRENO_OPENCL=<Path to OpenCLML SDK>
./tests/scripts/ci.py adreno -i
成功编译后,我们将进入 Docker 容器的 shell 环境。编译完成后会生成两个文件夹。
build-adreno:主机端的 TVM 编译器构建。
build-adreno-target:包含 Android 目标设备的组件。
libtvm_runtime.so:TVM 运行时库。
tvm_rpc:RPC 运行时环境工具。
rtvm:原生的独立工具。
在使用 Docker 环境时,Android 设备是与主机共享的。因此,主机上需要安装版本为 1.0.41 的 adb,因为 Docker 使用了相同版本。
也可以在 Docker 环境中检查 adb 设备的可用性。
user@ci-adreno-fpeqs:~$ adb devices
List of devices attached
aaaabbbb device
ccccdddd device
开发环境设置:手动#
手动构建过程需要分别构建主机和目标设备的组件。
以下命令将配置并构建主机编译器。
mkdir -p build
cd build
cp ../cmake/config.cmake .
# Enable RPC capability to communicate to remote device.
echo set\(USE_RPC ON\) >> config.cmake
# We use graph executor for any host(x86) side verification of the model.
echo set\(USE_GRAPH_EXECUTOR ON\) >> config.cmake
# Enable backtrace if possible for more ebug information on any crash.
echo set\(USE_LIBBACKTRACE AUTO\) >> config.cmake
# The target_host will be llvm.
echo set\(USE_LLVM ON\) >> config.cmake
此外,可以添加以下配置条目以支持 OpenCLML 编译。
export ADRENO_OPENCL=<Path to OpenCLML SDK>
echo set\(USE_CLML ${ADRENO_OPENCL}\) >> config.cmake
现在可以按照以下方式构建。
cmake ..
make
最后,可以导出 Python 路径,如下所示。
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
python3 -c "import tvm" # Verify tvm python package
现在,可以通过以下配置来配置并构建目标设备组件。目标构建需要安装 Android NDK。
请在此处阅读有关 Android NDK 安装 的文档:https://developer.android.com/ndk。
要获取 adb 工具的访问权限,您可以在此处查看 Android Debug Bridge 安装:https://developer.android.com/studio/command-line/adb。
mkdir -p build-adreno
cd build-adreno
cp ../cmake/config.cmake .
# Enable OpenCL backend.
echo set\(USE_OPENCL ON\) >> config.cmake
# Enable RPC functionality.
echo set\(USE_RPC ON\) >> config.cmake
# Build tvm_rpc tool that runs on target device.
echo set\(USE_CPP_RPC ON\) >> config.cmake
# Build native rtvm deploy tool.
echo set\(USE_CPP_RTVM ON\) >> config.cmake
# We use graph executor for deploying on devices like Android.
echo set\(USE_GRAPH_EXECUTOR ON\) >> config.cmake
# Backtrace enablement if possible.
echo set\(USE_LIBBACKTRACE AUTO\) >> config.cmake
# Adreno supports 32bit alignment for OpenCL allocations rather 64bit.
echo set\(USE_KALLOC_ALIGNMENT 32\) >> config.cmake
# Android build related defines.
echo set\(ANDROID_ABI arm64-v8a\) >> config.cmake
echo set\(ANDROID_PLATFORM android-28\) >> config.cmake
echo set\(MACHINE_NAME aarch64-linux-gnu\) >> config.cmake
此外,可以添加以下配置以支持 OpenCLML 编译。
export ADRENO_OPENCL=<Path to OpenCLML SDK>
echo set\(USE_CLML "${ADRENO_OPENCL}"\) >> config.cmake
echo set\(USE_CLML_GRAPH_EXECUTOR "${ADRENO_OPENCL}"\) >> config.cmake
对于 Android 目标构建,ANDROID_NDK_HOME 是依赖项,需要将其设置为环境变量。以下命令将构建 Adreno™ 目标组件。
cmake -DCMAKE_TOOLCHAIN_FILE="${ANDROID_NDK_HOME}/build/cmake/android.toolchain.cmake" \
-DANDROID_ABI=arm64-v8a \
-DANDROID_PLATFORM=android-28 \
-DCMAKE_SYSTEM_VERSION=1 \
-DCMAKE_FIND_ROOT_PATH="${ADRENO_OPENCL}" \
-DCMAKE_FIND_ROOT_PATH_MODE_PROGRAM=NEVER \
-DCMAKE_FIND_ROOT_PATH_MODE_LIBRARY=ONLY \
-DCMAKE_CXX_COMPILER="${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang++" \
-DCMAKE_C_COMPILER="${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang" \
-DMACHINE_NAME="aarch64-linux-gnu" ..
make tvm_runtime tvm_rpc rtvm
RPC 设置#
RPC 设置允许通过 TCP/IP 网络接口远程访问目标设备。RPC 设置在自动调优阶段至关重要,因为调优过程涉及在真实设备上运行自动生成的内核,并通过机器学习方法对其进行优化。有关 AutoTVM 的更多详细信息,请参阅 使用模板和 AutoTVM 进行自动调优。
RPC 设置还可用于通过 Python 接口或主机设备上的 tvmc 工具将编译后的模型部署到远程设备。
RPC 设置包含多个组件,如下所列。
TVM Tracker: TVM Tracker 是主机端的守护进程,用于管理远程设备并将其提供给主机端应用程序。应用程序可以连接到此 Tracker 并获取远程设备句柄以进行通信。
TVM RPC: TVM RPC 是在远程设备(在我们的案例中是 Android 设备)上运行的原生应用程序,它会向主机上运行的 TVM Tracker 注册自己。
因此,对于基于 RPC 的设置,我们需要在主机和目标设备上运行上述组件。以下部分将解释如何手动设置以及如何在 Docker 中使用自动化工具进行设置。
自动化 RPC 设置: 这里我们将解释如何在 Docker 环境中设置 RPC。
以下命令在 Docker 环境中启动 Tracker,Tracker 将监听端口 9190。
./tests/scripts/ci.py adreno -i # Launch a new shell on the anreno docker
source tests/scripts/setup-adreno-env.sh -e tracker -p 9190
现在,以下命令可以在 ID 为 abcdefgh 的远程 Android 设备上运行 TVM RPC。
./tests/scripts/ci.py adreno -i # Launch a new shell on adreno docker.
source tests/scripts/setup-adreno-env.sh -e device -p 9190 -d abcdefgh
此外,以下命令可用于在任何其他 Docker 终端上查询 RPC 设置的详细信息。
./tests/scripts/ci.py adreno -i # Launch a new shell on adreno docker.
source tests/scripts/setup-adreno-env.sh -e query -p 9190
手动 RPC 设置:
请参考教程 如何在 Adreno 上部署模型 以了解手动 RPC 环境设置。
至此,RPC 设置已完成,在主机 127.0.0.1 (rpc-tracker)和端口 9190 (rpc-port)上可用的 rpc-tracker。
命令行工具#
Here we describe entire compilation process using command line tools. TVM has command line utility tvmc to perform model import, auto tuning, compilation and deply over rpc. tvmc has many options to explore and try.
模型导入与调优: 使用以下命令从任何框架导入模型并进行自动调优。这里我们使用了来自 Keras 的模型,并通过 RPC 设置进行调优,最终生成调优日志文件 keras-resnet50.log。
python3 -m tvm.driver.tvmc tune --target="opencl -device=adreno" \
--target-host="llvm -mtriple=aarch64-linux-gnu" \
resnet50.h5 -o \
keras-resnet50.log \
--early-stopping 0 --repeat 30 --rpc-key android \
--rpc-tracker 127.0.0.1:9190 --trials 1024 \
--tuning-records keras-resnet50-records.log --tuner xgb
模型编译:
使用以下命令编译模型并生成 TVM 编译器输出。
python3 -m tvm.driver.tvmc compile \
--cross-compiler ${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang \
--target="opencl, llvm" --target-llvm-mtriple aarch64-linux-gnu --target-opencl-device adreno \
--tuning-records keras-resnet50.log -o keras-resnet50.tar resnet50.h5
启用 OpenCLML 卸载时,我们需要添加目标 clml,如下所示。调优日志对于 OpenCLML 卸载同样有效,因为 OpenCL 路径是任何未通过 OpenCLML 路径的算子的后备选项。调优日志将用于这些算子。
python3 -m tvm.driver.tvmc compile \
--cross-compiler ${ANDROID_NDK_HOME}/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android28-clang \
--target="opencl, clml, llvm" --desired-layout NCHW --target-llvm-mtriple aarch64-linux-gnu --target-opencl-device adreno \
--tuning-records keras-resnet50.log -o keras-resnet50.tar resnet50.h5
成功编译后,上述命令将生成 keras-resnet50.tar。这是一个包含内核共享库(mod.so)、图结构 JSON(mod.json)和参数二进制文件(mod.params)的压缩归档文件。
部署并在目标设备上运行:
可以在 Android 目标设备上以 RPC 方式或原生部署方式运行编译后的模型。
可以使用以下 tvmc 命令通过基于 RPC 的设置部署到远程目标设备。
python3 -m tvm.driver.tvmc run --device="cl" keras-resnet50.tar \
--rpc-key android --rpc-tracker 127.0.0.1:9190 --print-time
基于 tvmc 的运行提供了更多选项,可以以各种模式(如填充、随机等)初始化输入。
基于 tvmc 的部署通常是通过 RPC 设置在远程主机上快速验证目标设备上的编译模型。
生产环境通常使用原生部署环境,如 Android JNI 或 CPP 原生环境。这里我们需要使用交叉编译的 tvm_runtime 接口来部署 TVM 编译输出,即 TVMPackage。
TVM 提供了独立的工具 rtvm,用于在 ADB shell 中原生部署和运行模型。构建过程会在 build-adreno-target 目录下生成此工具。有关此工具的更多详细信息,请参阅 rtvm。
在集成到现有的 Android 应用程序时,TVM 提供了多种选项。对于 JNI 或 CPP 原生环境,可以使用 C Runtime API。您也可以参考 rtvm 的简化接口 TVMRunner。
Python 接口#
本节将解释如何使用 Python 接口进行模型导入、自动调优、编译和运行。TVM 提供了通过 tvmc 抽象的高级接口以及低级的 Relay API。我们将详细讨论这两种方式。
TVMC 接口:
使用 tvmc Python 接口时,我们首先加载一个模型,生成 TVMCModel。TVMCModel 将用于自动调优以生成调优缓存。编译过程使用 TVMCModel 和调优缓存(可选)生成 TVMCPackage。现在,TVMCPackage 可以保存到文件系统,也可以用于在目标设备上部署和运行。
请参考以下教程了解如何使用 TVMC 在 Adreno 上部署模型:如何使用 TVMC 在 Adreno 上部署模型。
保存的 TVMCPackage 也可以使用 rtvm 工具进行原生部署。
此外,请参阅 tvmc 文档以了解有关 API 接口的更多详细信息。
Relay 接口:
Relay API 接口提供了对 TVM 编译器接口的低级 API 访问。与 tvmc 接口类似,Relay API 接口提供了各种前端 API,用于将模型转换为 Relay Module。Relay Module 将用于各种转换,如精度转换、CLML 卸载以及其他自定义转换(如果有)。生成的 Module 也将用于自动调优。最后,我们使用 relay.build API 生成库模块。从这个库模块中,我们可以导出编译产物,如模块共享库(mod.so)、参数(mod.params)和 JSON 图结构(mod.json)。此库模块将用于创建图运行时,以在目标设备上部署和运行。
请参考教程 如何在 Adreno 上部署模型 以获取逐步的详细说明。
此外,TVM 还通过 TVM4J 支持 Java 接口。
应用程序集成#
TVM 编译输出表示为模块共享库(mod.so)、图结构 JSON(mod.json)和参数(mod.params)。TVMPackage 的归档表示也包含相同的内容。
通常,基于 CPP/C 的接口足以满足任何 Android 应用程序集成的需求。
TVM 原生提供了 c_runtime_api,用于加载 TVM 编译的模块并运行它。
或者,您也可以参考 cpp_rtvm 的 TVMRunner 接口,它是进一步简化的版本。
高级用法#
本节详细介绍了在 TVM 上使用 Adreno™ 目标时的一些高级用法和附加信息。
生成的源代码检查#
除了标准的 TVM 编译产物内核库(mod.so)、图结构(mod.json)和参数(mod.params)外,还可以从库句柄中生成 OpenCL 内核源代码、CLML 卸载图等,如下所示。TVM 编译输出组织为 TVM 模块,并导入了许多其他 TVM 模块。
以下代码片段可以以 JSON 格式导出 CLML 子图。
# Look for "clml" typed module imported.
clml_modules = list(filter(lambda mod: mod.type_key == "clml", lib.get_lib().imported_modules))
# Loop through all clml sub graphs and dump the json formatted CLML sub graphs.
for cmod in clml_modules:
print("CLML Src:", cmod.get_source())
类似地,以下代码片段可以从编译的 TVM 模块中提取 OpenCL 内核源代码。
# Similarly we can dump open kernel source too as shown below
# Look for "opencl" typed module imported.
opencl_modules = list(filter(lambda mod: mod.type_key == "opencl", lib.get_lib().imported_modules))
# Now dump kernel source for each OpenCL targetted sub graph.
for omod in opencl_modules:
print("OpenCL Src:", omod.get_source())
精度#
为特定工作负载选择合适的精度可以大大提高解决方案的效率,将精度和速度的初始平衡转移到问题的优先级一侧。
可以选择 float16、float16_acc32 (混合精度)或 float32 (标准精度)。
Float16
为了利用 GPU 硬件功能并享受半精度计算和内存管理的优势,可以将具有浮点运算的原始模型转换为使用半精度运算的模型。选择较低的精度会对模型的性能产生积极影响,但也可能导致模型的准确性下降。
要进行转换,您需要在通过任何前端生成 Relay 模块后立即调用 Adreno 特定的转换 API。
from tvm.driver.tvmc.transform import apply_graph_transforms
mod = apply_graph_transforms(
mod,
{
"mixed_precision": True,
"mixed_precision_ops": ["nn.conv2d", "nn.dense"],
"mixed_precision_calculation_type": "float16",
"mixed_precision_acc_type": "float16",
},
)
tvm.driver.tvmc.transform.apply_graph_transforms 是 ToMixedPrecision pass 的简化 API,用于获得所需的精度。
然后可以以任何方便的方式编译我们的模型。
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(
mod, target_host=target_host, target=target, params=params
)
使用 tvmc Python 接口时,以下参数启用精度转换为 float16。
mixed_precision = True,
mixed_precision_ops = ["nn.conv2d", "nn.dense"],
mixed_precision_calculation_type = "float16",
mixed_precision_acc_type = "float16"
类似地,tvmc 命令行接口提供了以下列出的选项。
--mixed-precision
--mixed-precision-ops nn.conv2d nn.dense
--mixed-precision-calculation-type float16
--mixed-precision-acc-type float16
float16_acc32 (Mixed Precision)
ToMixedPrecision pass 遍历网络并将网络拆分为处理 float 或 float16 数据类型的操作集群。这些集群由三种类型的操作定义: - 始终转换为 float16 数据类型的操作 - 如果它们跟随转换后的集群,则可以转换的操作 - 永远不会转换为 float16 数据类型的操作 此列表在 relay/transform/mixed_precision.py 中的 ToMixedPrecision 实现中定义,并且可以由用户覆盖。
ToMixedPrecision 方法是一种将 FP32 Relay 图转换为 FP16 版本(具有 FP16 或 FP32 累加数据类型)的 pass。进行此转换有助于减小模型大小,因为它将权重的预期大小减半(FP16_acc16 情况)。
ToMixedPrecision pass 的使用被简化为如下所示的简单调用。
from tvm.driver.tvmc.transform import apply_graph_transforms
mod = apply_graph_transforms(
mod,
{
"mixed_precision": True,
"mixed_precision_ops": ["nn.conv2d", "nn.dense"],
"mixed_precision_calculation_type": "float16",
"mixed_precision_acc_type": "float32",
},
)
tvm.driver.tvmc.transform.apply_graph_transforms 是 ToMixedPrecision pass 的简化 API,用于获得所需的精度。
然后可以以任何方便的方式编译我们的模型。
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(
mod, target_host=target_host, target=target, params=params
)
使用 tvmc Python 接口时,以下参数启用精度转换为 float16。
mixed_precision = True,
mixed_precision_ops = ["nn.conv2d", "nn.dense"],
mixed_precision_calculation_type = "float16",
mixed_precision_acc_type = "float32"
类似地,tvmc 命令行接口提供了以下列出的选项。
--mixed-precision
--mixed-precision-ops nn.conv2d nn.dense
--mixed-precision-calculation-type float16
--mixed-precision-acc-type float32