理解 Relax 抽象#
Relax 是 Apache TVM Unity 策略中使用的一种计算图抽象工具,它有助于对 ML 模型进行端到端的优化。Relax 的主要目标是描述 ML 模型的结构和数据流,包括模型各部分之间的依赖关系和相互关系,以及如何在硬件上执行模型。
端到端模型执行#
在本章中,将使用以下模型作为示例。这是包含两个线性算子的两层神经网络,并采用了 ReLU 激活函数。
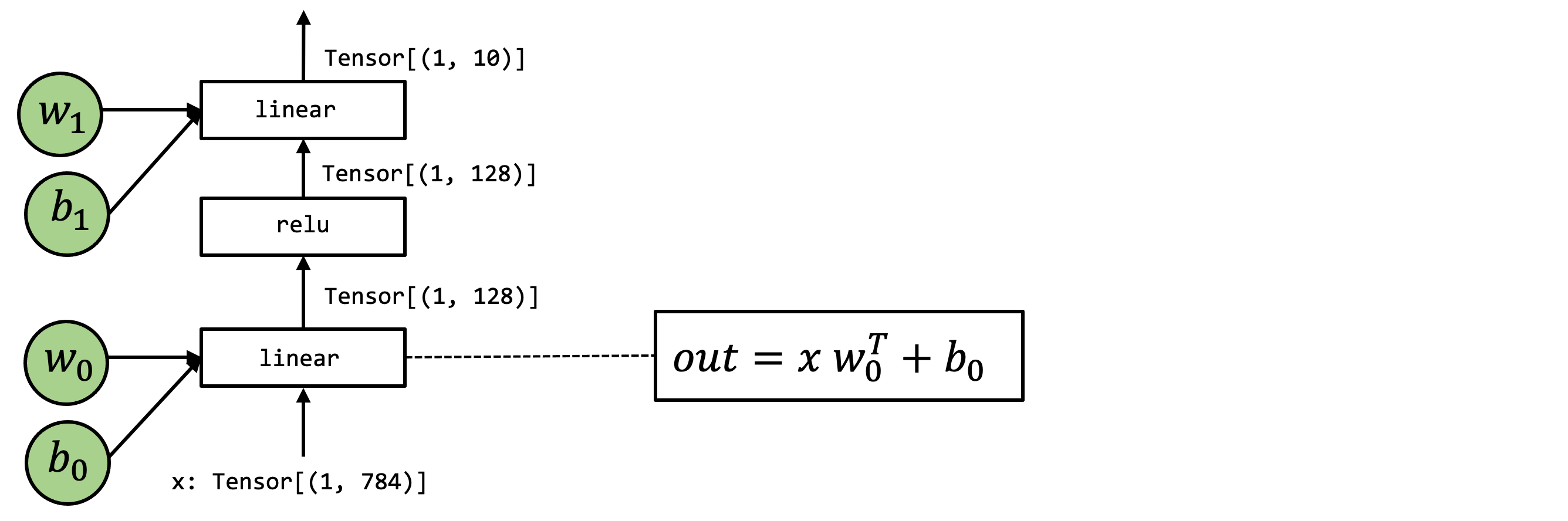
高级运算表示#
首先回顾该模型的 Numpy 实现。
def numpy_mlp(data, w0, b0, w1, b1):
lv0 = data @ w0 + b0
lv1 = np.maximum(lv0, 0)
lv2 = lv1 @ w1 + b1
return lv2
上述示例代码展示了执行端到端模型运算的高级数组运算。当然,可以使用 Relax 按照以下方式重写上述代码:
from tvm.script import relax as R
@R.function
def relax_mlp(
data: R.Tensor(("n", 784), dtype="float32"),
w0: R.Tensor((784, 128), dtype="float32"),
b0: R.Tensor((128,), dtype="float32"),
w1: R.Tensor((128, 10), dtype="float32"),
b1: R.Tensor((10,), dtype="float32"),
) -> R.Tensor(("n", 10), dtype="float32"):
with R.dataflow():
lv0 = R.matmul(data, w0) + b0
lv1 = R.nn.relu(lv0)
lv2 = R.matmul(lv1, w1) + b1
R.output(lv2)
return lv2
低层次集成#
然而,从机器学习编译(machine learning compilation,MLC)的角度来看,希望能够深入了解这些数组计算背后的细节。
为了详细说明底层细节,将再次以低级 numpy 为例进行编写。
在必要时,将使用循环而非数组函数来演示可能的循环计算。只要有可能,总是通过 numpy.empty 显式地分配数组并传递它们。下面的代码块展示了同一模型的低级 numpy 实现。
def lnumpy_linear(X: np.ndarray, W: np.ndarray, B: np.ndarray, Z: np.ndarray):
n, m, K = X.shape[0], W.shape[1], X.shape[1]
Y = np.empty((n, m), dtype="float32")
for i in range(n):
for j in range(m):
for k in range(K):
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + X[i, k] * W[k, j]
for i in range(n):
for j in range(m):
Z[i, j] = Y[i, j] + B[j]
def lnumpy_relu0(X: np.ndarray, Y: np.ndarray):
n, m = X.shape
for i in range(n):
for j in range(m):
Y[i, j] = np.maximum(X[i, j], 0)
def lnumpy_mlp(data, w0, b0, w1, b1):
n = data.shape[0]
lv0 = np.empty((n, 128), dtype="float32")
lnumpy_matmul(data, w0, b0, lv0)
lv1 = np.empty((n, 128), dtype="float32")
lnumpy_relu(lv0, lv1)
out = np.empty((n, 10), dtype="float32")
lnumpy_matmul(lv1, w1, b1, out)
return out
考虑到低级的 NumPy 示例,现在准备介绍针对端到端模型执行的 Relax 抽象。下面的代码块展示了该模型的 TVMScript 实现。
@I.ir_module
class Module:
@T.prim_func(private=True)
def linear(x: T.handle, w: T.handle, b: T.handle, z: T.handle):
M, N, K = T.int64(), T.int64(), T.int64()
X = T.match_buffer(x, (M, K), "float32")
W = T.match_buffer(w, (K, N), "float32")
B = T.match_buffer(b, (N,), "float32")
Z = T.match_buffer(z, (M, N), "float32")
Y = T.alloc_buffer((M, N), "float32")
for i, j, k in T.grid(M, N, K):
with T.block("Y"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[v_i, v_j] = T.float32(0.0)
Y[v_i, v_j] = Y[v_i, v_j] + X[v_i, v_k] * W[v_k, v_j]
for i, j in T.grid(M, N):
with T.block("Z"):
v_i, v_j = T.axis.remap("SS", [i, j])
Z[v_i, v_j] = Y[v_i, v_j] + B[v_j]
@T.prim_func(private=True)
def relu(x: T.handle, y: T.handle):
M, N = T.int64(), T.int64()
X = T.match_buffer(x, (M, N), "float32")
Y = T.match_buffer(y, (M, N), "float32")
for i, j in T.grid(M, N):
with T.block("Y"):
v_i, v_j = T.axis.remap("SS", [i, j])
Y[v_i, v_j] = T.max(X[v_i, v_j], T.float32(0.0))
@R.function
def main(
x: R.Tensor(("n", 784), dtype="float32"),
w0: R.Tensor((784, 256), dtype="float32"),
b0: R.Tensor((256,), dtype="float32"),
w1: R.Tensor((256, 10), dtype="float32"),
b1: R.Tensor((10,), dtype="float32")
) -> R.Tensor(("n", 10), dtype="float32"):
cls = Module
n = T.int64()
with R.dataflow():
lv = R.call_tir(cls.linear, (x, w0, b0), out_sinfo=R.Tensor((n, 256), dtype="float32"))
lv1 = R.call_tir(cls.relu, (lv0,), out_sinfo=R.Tensor((n, 256), dtype="float32"))
lv2 = R.call_tir(cls.linear, (lv1, w1, b1), out_sinfo=R.Tensor((b, 10), dtype="float32"))
R.output(lv2)
return lv2
以上代码包含多种函数:元张量函数 (T.prim_func) 和 R.function (relax 函数)。Relax 函数是一种新的抽象类型,代表高层次的神经网络执行。
请注意,上述 Relax 模块原生支持符号形状,例如在 main 函数中的张量形状中看到的 "n",以及 linear 函数中的 M、N 和 K。这是 Relax 抽象的关键特性,它使得编译器能够全局追踪张量运算和函数调用之间的动态形状关系。
再次查看 TVMScript 代码和底层 numpy 代码的并列对比,并检查相应的元素是非常有帮助的,将逐一详细地分析它们。由于已经学习了元张量函数,将专注于高级执行部分。
Relax 的关键要素#
本节将介绍 Relax 抽象化的关键要素以及它如何实现 ML 编译器中的优化。
结构信息#
在 Relax 中,结构信息是新概念,它表示不同类型的 relax 表达式。这些类型可以是 TensorStructInfo、TupleStructInfo 等。在上面的例子中,使用 TensorStructInfo (在 TVMScript 中简称为 R.Tensor)来表示输入、输出以及中间结果的张量的形状和数据类型。
R.call_tir#
R.call_tir 函数是 Relax 中的新抽象概念,允许在同一 IRModule 中调用元张量函数。这是 Relax 的关键特性,它支持从高层神经网络层到低层张量运算的跨级抽象。以上述代码中的一行为例:
lv = R.call_tir(cls.linear, (x, w0, b0), out_sinfo=R.Tensor((n, 256), dtype="float32"))
要解释 R.call_tir 是如何工作的,回顾一下其等效的低级 NumPy 实现,如下所示:
lv0 = np.empty((n, 256), dtype="float32")
lnumpy_linear(x, w0, b0, lv0)
具体来说,call_tir 函数首先分配输出张量 res,然后将 inputs 和 输出传递给 prim_func。执行 prim_func 后,结果会被填充到 res 中,随后便可以返回该结果。
这种约定被称为 目标传递 (destination passing),其核心思想是输入和输出在外部显式分配并传递给低级的元函数。这种风格通常用于低级库设计中,以便更高级的框架可以处理内存分配的决定。需要注意的是,并非所有的张量运算都可以以这种方式呈现(特别是,有些算子的输出形状依赖于输入)。然而,在实践中,当可能时,以这种方式编写低级函数通常是有益的。
数据流程块#
在 relax 函数中另一个重要的元素是 R.dataflow() 范围注释。
with R.dataflow():
lv = R.call_tir(cls.linear, (x, w0, b0), out_sinfo=R.Tensor((n, 256), dtype="float32"))
lv1 = R.call_tir(cls.relu, (lv0,), out_sinfo=R.Tensor((n, 256), dtype="float32"))
lv2 = R.call_tir(cls.linear, (lv1, w1, b1), out_sinfo=R.Tensor((b, 10), dtype="float32"))
R.output(lv2)
在讨论数据流块之前,首先介绍“纯函数”和“副作用”的概念。函数是“纯的”或者说是“无副作用的”,如果它满足以下条件:
它仅从输入中读取数据,并通过输出返回结果。
它不会改变程序的其他部分(比如增加 “全局计数器”)。
例如,所有的 R.call_tir 函数都是纯函数,因为它们仅从输入读取数据并将输出写入另一个新分配的张量。然而,原地操作不是纯函数,换句话说,它们是有副作用的函数,因为它们会改变现有的中间或输入张量。
数据流块是一种方法,用于标记程序的计算图区域。具体来说,在数据流块内部,所有运算都需要是无副作用的。在数据流块外部,运算可以包含副作用。
备注
常见的问题是,为什么需要手动标记数据流块而不是自动推断它们。采取这种方法有两个主要理由:
数据流块的自动推断可能会面临挑战且不够精确,尤其是在处理对打包函数(如 cuBLAS 集成)的调用时。通过手动标记数据流块,可以使得编译器能够准确理解并优化程序的数据流。
许多优化只能在数据流块内应用。例如,融合优化仅限于单个数据流块内的运算。如果编译器错误地推断数据流边界,可能会错过关键的优化机会,从而可能影响程序的性能。
通过允许手动标记数据流块,确保编译器拥有最准确的信息进行处理,从而带来更有效的优化。