VTA 入门#
原作者: Thierry Moreau|修改 xinetzone
这是关于如何使用 TVM 编程 VTA 设计的入门教程。
在本教程中,将演示在 VTA 设计的向量 ALU 上实现向量加法的基本 TVM 工作流。此过程包括将计算 lower 到低级加速器运算所需的特定调度变换。
首先,需要导入 TVM,这是深度学习优化编译器。还需要导入 VTA python 包,其中包含针对 TVM 的 VTA 特定扩展,以实现 VTA 设计。
import set_env
import os
import tvm
from tvm import te
import vta
from tvm.ir.module import IRModule
from tvm.script import tir as T
import numpy as np
加载 VTA 参数#
VTA 是模块化和可定制的设计。因此,用户可以自由地修改影响硬件设计布局的高级硬件参数。这些参数在 tvm/3rdparty/vta-hw/config/vta_config.json 中通过它们的 log2 值指定。
这些 VTA 参数可以通过 vta.get_env 函数加载。
最后,TVM 目标也在 vta_config.json 文件中指定。当设置为 sim 时,执行将发生在 VTA 仿真器行为内。如果您想在 Pynq FPGA 开发平台上运行本教程,请遵循 VTA 基于 Pynq 的测试设置 指南。
env = vta.get_env()
FPGA 编程#
当针对 Pynq FPGA 开发板时,需要使用 VTA bitstream 配置该板。
需要 TVM RPC 模块和 VTA 仿真器模块:
from vta.testing import simulator # 此处一定要有
警告
若 vta 是 sim 模式,一定要载入 simulator 模块,否则会触发异常。
从操作系统环境中读取 Pynq RPC 主机 IP 地址和端口号:
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
在 Pynq 上配置 bitstream 和运行时系统,以匹配 vta_config.json 文件指定的 VTA 配置。
env.TARGET
'sim'
if env.TARGET in ["pynq", "de10nano"]:
# 确保使用 RPC=1 编译 TVM
assert tvm.runtime.enabled("rpc")
remote = tvm.rpc.connect(host, port)
# 重新配置 JIT runtime
vta.reconfig_runtime(remote)
# 用预编译的 VTA bitstream 编程 FPGA。
# 通过将 path 传递给 bitstream 文件而不是 None,
# 您可以使用自定义 bitstream 编程 FPGA。
vta.program_fpga(remote, bitstream=None)
# 在仿真模式中,在本地托管 RPC 服务器。
elif env.TARGET in ("sim", "tsim", "intelfocl"):
remote = tvm.rpc.LocalSession()
if env.TARGET in ["intelfocl"]:
# program intelfocl aocx
vta.program_fpga(remote, bitstream="vta.bitstream")
准备数据#
为了验证计算的正确性,需要准备一些数据, 随机初始化 A 和 B 数组,int 范围为 \((-128, 128]\):
m = 16
n = 1024
A_orig = np.random.randint(-128, 128, size=(m, n)).astype(env.acc_dtype)
B_orig = np.random.randint(-128, 128, size=(m, n)).astype(env.acc_dtype)
为了适应于 VTA 设备,需要应用 packing,将 A 和 B 数组从 2D 到 4D packed layout:
A_packed = A_orig.reshape(m//env.BATCH, env.BATCH, n//env.BLOCK_OUT, env.BLOCK_OUT).transpose((0, 2, 1, 3))
B_packed = B_orig.reshape(m//env.BATCH, env.BATCH, n//env.BLOCK_OUT, env.BLOCK_OUT).transpose((0, 2, 1, 3))
计算声明#
第一步,需要描述计算。TVM 采用张量语义,每个中间结果表示为多维数组。用户需要描述生成输出张量的计算规则。
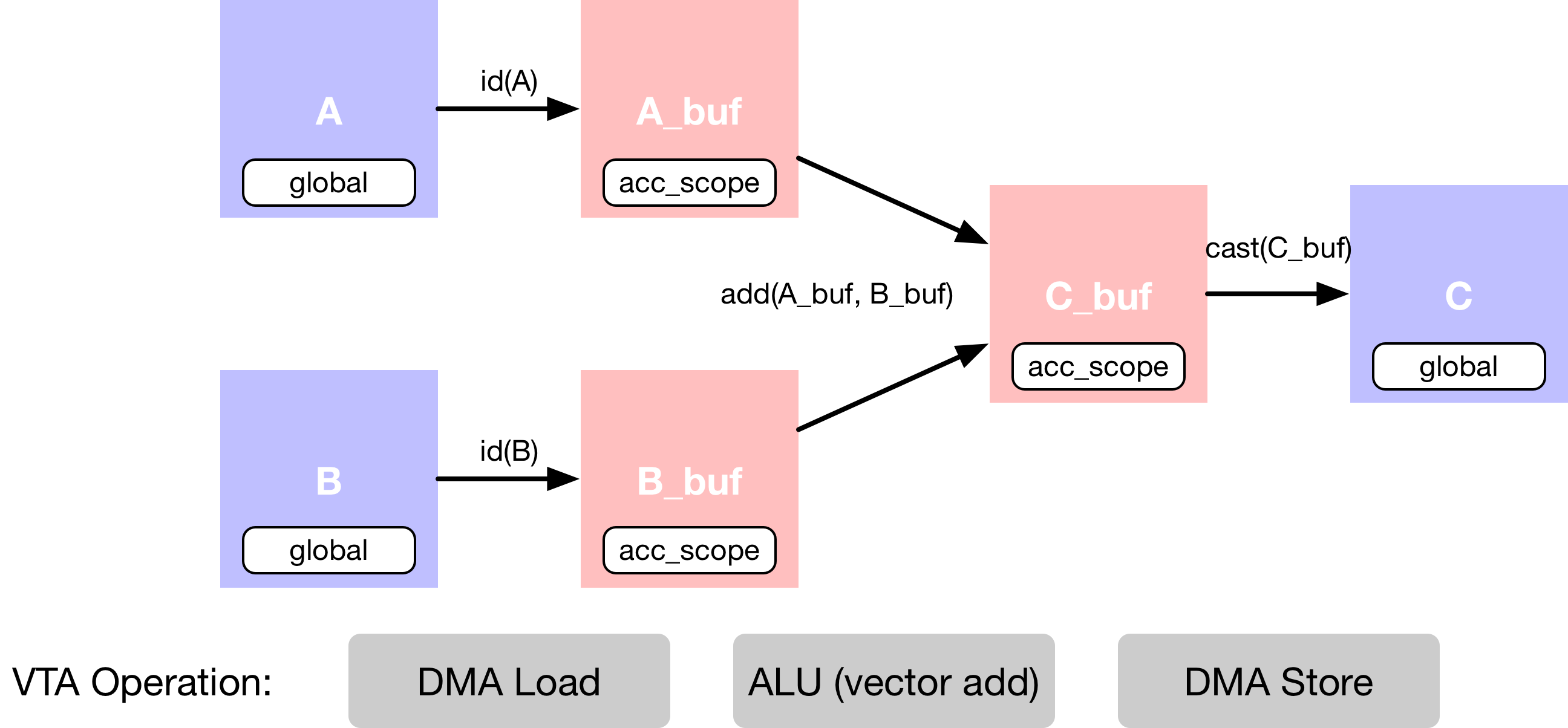
在这个例子中,描述了向量加法,它需要多个计算阶段,如下面的数据流程图所示。
首先,描述存在于 main memory 中的输入张量
A和B。其次,需要声明中间张量
A_buf和B_buf,它们将位于 VTA 的 on-chip buffers 中。有了这个额外的计算阶段,就可以显式地分阶段进行 cached 的读写操作。第三,描述向量加法运算:
C_buf = A_buf + B_buf。最后的运算是强制转换并复制回 DRAM,到结果张量
C中。
Input 占位符#
以平铺(tiled)数据格式描述占位符张量 A 和 B,以匹配 VTA 向量 ALU 施加的数据布局要求。
对于 VTA 的一般用途的运算,如 ALU 加法,tile 大小为 (env.BATCH, env.BLOCK_OUT)。维度在 vta_config.json 配置文件中指定,默认设置为 (1, 16) 向量。
# 输出通道因子 m -总共 64 x 16 = 1024 输出通道
_m = n//env.BLOCK_OUT
# Batch 因子 o - 总共 16 x 1 = 1
_o = m//env.BATCH
# VTA 向量数据 shape
shape = (_o, _m, env.BATCH, env.BLOCK_OUT)
shape
(16, 64, 1, 16)
查看 env.acc_dtype 和 env.inp_dtype:
env.acc_dtype, env.inp_dtype, env.out_dtype, env.wgt_dtype
('int32', 'int8', 'int8', 'int8')
此外,A 和 B 的数据类型也需要匹配 env.acc_dtype,由 vta_config.json 文件设置为 32 位整型。
# 平铺 A, B 占位符张量数据
A = te.placeholder(shape, name="A", dtype=env.acc_dtype)
B = te.placeholder(shape, name="B", dtype=env.acc_dtype)
A
Tensor(shape=[16, 64, 1, 16], op.name=A)
Copy Buffers#
硬件加速器的特点之一是,必须对 on-chip memory 进行显式管理。这意味着需要描述中间张量 A_buf 和 B_buf,它们可以具有与原始占位符张量 A 和 B 不同的内存作用域。
稍后在调度阶段,可以告诉编译器 A_buf 和 B_buf 将存在于 VTA 的 on-chip buffer(SRAM)中,而 A 和 B 将存在于 main memory(DRAM)中。将 A_buf 和 B_buf 描述为恒等函数计算的运算结果。这可以被编译器解释为 cached 的读运算。
# A copy buffer
A_buf = te.compute(shape, lambda *i: A[i], "A_buf")
# B copy buffer
B_buf = te.compute(shape, lambda *i: B[i], "B_buf")
A_buf
Tensor(shape=[16, 64, 1, 16], op.name=A_buf)
ALU 加法#
现在可以用另一个 compute 运算来描述向量加法结果张量 C。compute 函数采用张量的形状,以及描述张量每个位置的计算规则的 lambda 函数。
此阶段没有计算发生,因为只是声明了计算应该如何完成。
# 描述 VTA 中的 ALU 加法
fcompute = lambda *i: A_buf[i].astype(env.acc_dtype) + B_buf[i].astype(env.acc_dtype)
C_buf = te.compute(shape, fcompute, name="C_buf")
Casting 结果#
计算完成后,需要将 VTA 计算的结果发送回主存储器(main memory)
内存存储限制
VTA 的特点之一是,它只支持窄化(narrow) env.inp_dtype 数据类型格式的 DRAM 存储。这让我们能够减少内存传输的数据 footprint(详见基本矩阵乘法的例子)。
对窄化的输入激活数据格式执行最后一个 typecast 运算。
# 转换为输出类型,并发送到 main memory
fcompute = lambda *i: C_buf[i].astype(env.inp_dtype)
C = te.compute(shape, fcompute, name="C")
这就结束了本教程的计算声明部分。
调度计算#
虽然上面的几行描述了计算规则,但我们可以通过许多方式得到 C。TVM 要求用户提供名为 调度 (schedule) 的计算实现。
调度是对原始计算的一组变换,它在不影响正确性的情况下变换计算的实现。这个简单的 VTA 编程教程旨在演示基本的调度变换,将原始调度映射到 VTA 硬件原语(primitives)。
默认调度#
在构造了调度之后,默认情况下,调度会以如下方式计算 C:
func_name = "add"
te_func = te.create_prim_func([A, B, C]).with_attr({"global_symbol": func_name})
MyModule = IRModule({func_name: te_func})
sch = tvm.tir.Schedule(MyModule)
sch.mod.show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def add(A: T.Buffer((16, 64, 1, 16), "int32"), B: T.Buffer((16, 64, 1, 16), "int32"), C: T.Buffer((16, 64, 1, 16), "int8")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
A_buf = T.alloc_buffer((16, 64, 1, 16), "int32")
B_buf = T.alloc_buffer((16, 64, 1, 16), "int32")
C_buf = T.alloc_buffer((16, 64, 1, 16), "int32")
for i0, i1, i2, i3 in T.grid(16, 64, 1, 16):
with T.block("A_buf"):
v_i0, v_i1, v_i2, v_i3 = T.axis.remap("SSSS", [i0, i1, i2, i3])
T.reads(A[v_i0, v_i1, v_i2, v_i3])
T.writes(A_buf[v_i0, v_i1, v_i2, v_i3])
A_buf[v_i0, v_i1, v_i2, v_i3] = A[v_i0, v_i1, v_i2, v_i3]
for i0, i1, i2, i3 in T.grid(16, 64, 1, 16):
with T.block("B_buf"):
v_i0, v_i1, v_i2, v_i3 = T.axis.remap("SSSS", [i0, i1, i2, i3])
T.reads(B[v_i0, v_i1, v_i2, v_i3])
T.writes(B_buf[v_i0, v_i1, v_i2, v_i3])
B_buf[v_i0, v_i1, v_i2, v_i3] = B[v_i0, v_i1, v_i2, v_i3]
for i0, i1, i2, i3 in T.grid(16, 64, 1, 16):
with T.block("C_buf"):
v_i0, v_i1, v_i2, v_i3 = T.axis.remap("SSSS", [i0, i1, i2, i3])
T.reads(A_buf[v_i0, v_i1, v_i2, v_i3], B_buf[v_i0, v_i1, v_i2, v_i3])
T.writes(C_buf[v_i0, v_i1, v_i2, v_i3])
C_buf[v_i0, v_i1, v_i2, v_i3] = A_buf[v_i0, v_i1, v_i2, v_i3] + B_buf[v_i0, v_i1, v_i2, v_i3]
for i0, i1, i2, i3 in T.grid(16, 64, 1, 16):
with T.block("C"):
v_i0, v_i1, v_i2, v_i3 = T.axis.remap("SSSS", [i0, i1, i2, i3])
T.reads(C_buf[v_i0, v_i1, v_i2, v_i3])
T.writes(C[v_i0, v_i1, v_i2, v_i3])
C[v_i0, v_i1, v_i2, v_i3] = T.Cast("int8", C_buf[v_i0, v_i1, v_i2, v_i3])
s = te.create_schedule(C.op)
# simulator.clear_stats()
# cost = evaluator(a, b, c)
# stats = simulator.stats()
虽然此调度是合理的,但它不会编译到 VTA。为了获得正确的代码生成(code generation),需要应用调度原语(scheduling primitives)和代码注解(code annotation),将调度变换为可以直接 lower 到 VTA 硬件 intrinsics。其中包括:
DMA copy 运算将把全局作用域的张量复制到局部作用域的张量。
执行向量加法的向量 ALU 运算。
Buffer 作用域#
首先,设置复制 buffer 的作用域,以指示 TVM 这些中间张量将存储在 VTA 的 on-chip SRAM buffer 中。下面,告诉 TVM A_buf、B_buf、C_buf 将存在于 VTA 的 on-chip accumulator buffer 中,该 buffer 作为 VTA 的通用寄存器(register)文件。
将中间张量的作用域设置为 VTA 的 on-chip accumulator buffer
s[A_buf].set_scope(env.acc_scope)
s[B_buf].set_scope(env.acc_scope)
s[C_buf].set_scope(env.acc_scope)
tvm.lower(s, [A, B, C], simple_mode=True).show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer((16, 64, 1, 16), "int32"), B: T.Buffer((16, 64, 1, 16), "int32"), C: T.Buffer((16, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": T.bool(True), "tir.noalias": T.bool(True)})
A_buf = T.allocate([32768], "int32", "local.acc_buffer")
A_buf_1 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_1: T.int32 = i0 * 1024 + i1 * 16 + i3
A_1 = T.Buffer((16384,), "int32", data=A.data)
A_buf_1[cse_var_1] = A_1[cse_var_1]
A_buf_2 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_2: T.int32 = i0 * 1024 + i1 * 16 + i3
B_1 = T.Buffer((16384,), "int32", data=B.data)
A_buf_2[cse_var_2 + 16384] = B_1[cse_var_2]
A_buf_3 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_3: T.int32 = i0 * 1024 + i1 * 16 + i3
A_buf_3[cse_var_3] = A_buf_1[cse_var_3] + A_buf_2[cse_var_3 + 16384]
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_4: T.int32 = i0 * 1024 + i1 * 16 + i3
C_1 = T.Buffer((16384,), "int8", data=C.data)
C_1[cse_var_4] = T.Cast("int8", A_buf_3[cse_var_4])
DMA 传输#
需要调度 DMA 传输,以便将存储在 DRAM 中的数据在 VTA 片上 buffer 之间来回移动。插入 dma_copy pragmas 来告诉编译器,复制运算将通过 DMA 批量执行,这在硬件加速器中很常见。
使用 DMA pragma 标记 buffer 副本,将复制循环映射到 DMA transfer 运算:
s[A_buf].pragma(s[A_buf].op.axis[0], env.dma_copy)
s[B_buf].pragma(s[B_buf].op.axis[0], env.dma_copy)
s[C].pragma(s[C].op.axis[0], env.dma_copy)
tvm.lower(s, [A, B, C], simple_mode=True).show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer((16, 64, 1, 16), "int32"), B: T.Buffer((16, 64, 1, 16), "int32"), C: T.Buffer((16, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": T.bool(True), "tir.noalias": T.bool(True)})
A_buf = T.allocate([32768], "int32", "local.acc_buffer")
i0 = T.int32()
A_buf_1 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
with T.attr(T.iter_var(i0, None, "DataPar", ""), "pragma_dma_copy", 1):
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_1: T.int32 = i0 * 1024 + i1 * 16 + i3
A_1 = T.Buffer((16384,), "int32", data=A.data)
A_buf_1[cse_var_1] = A_1[cse_var_1]
i0_1 = T.int32()
A_buf_2 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
with T.attr(T.iter_var(i0_1, None, "DataPar", ""), "pragma_dma_copy", 1):
for i0_1, i1, i3 in T.grid(16, 64, 16):
cse_var_2: T.int32 = i0_1 * 1024 + i1 * 16 + i3
B_1 = T.Buffer((16384,), "int32", data=B.data)
A_buf_2[cse_var_2 + 16384] = B_1[cse_var_2]
A_buf_3 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
for i0_2, i1, i3 in T.grid(16, 64, 16):
cse_var_3: T.int32 = i0_2 * 1024 + i1 * 16 + i3
A_buf_3[cse_var_3] = A_buf_1[cse_var_3] + A_buf_2[cse_var_3 + 16384]
i0_2 = T.int32()
T.attr(T.iter_var(i0_2, None, "DataPar", ""), "pragma_dma_copy", 1)
for i0_2, i1, i3 in T.grid(16, 64, 16):
cse_var_4: T.int32 = i0_2 * 1024 + i1 * 16 + i3
C_1 = T.Buffer((16384,), "int8", data=C.data)
C_1[cse_var_4] = T.Cast("int8", A_buf_3[cse_var_4])
ALU 运算#
VTA 有向量 ALU,可以在累加器 buffer 中对张量执行向量运算。为了告诉 TVM 给定的运算需要映射到 VTA 的 vector ALU,需要显式地用 env.alu pragma 标记 vector 加法循环。
告诉 TVM 计算需要在 VTA 的向量 ALU 上执行:
s[C_buf].pragma(C_buf.op.axis[0], env.alu)
# 查看最终的 schedule
tvm.lower(s, [A, B, C], simple_mode=True).show()
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer((16, 64, 1, 16), "int32"), B: T.Buffer((16, 64, 1, 16), "int32"), C: T.Buffer((16, 64, 1, 16), "int8")):
T.func_attr({"from_legacy_te_schedule": T.bool(True), "tir.noalias": T.bool(True)})
A_buf = T.allocate([32768], "int32", "local.acc_buffer")
i0 = T.int32()
A_buf_1 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
with T.attr(T.iter_var(i0, None, "DataPar", ""), "pragma_dma_copy", 1):
for i0, i1, i3 in T.grid(16, 64, 16):
cse_var_1: T.int32 = i0 * 1024 + i1 * 16 + i3
A_1 = T.Buffer((16384,), "int32", data=A.data)
A_buf_1[cse_var_1] = A_1[cse_var_1]
i0_1 = T.int32()
A_buf_2 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
with T.attr(T.iter_var(i0_1, None, "DataPar", ""), "pragma_dma_copy", 1):
for i0_1, i1, i3 in T.grid(16, 64, 16):
cse_var_2: T.int32 = i0_1 * 1024 + i1 * 16 + i3
B_1 = T.Buffer((16384,), "int32", data=B.data)
A_buf_2[cse_var_2 + 16384] = B_1[cse_var_2]
i0_2 = T.int32()
A_buf_3 = T.Buffer((16384,), "int32", data=A_buf, scope="local.acc_buffer", align=16)
with T.attr(T.iter_var(i0_2, None, "DataPar", ""), "pragma_alu", 1):
for i0_2, i1, i3 in T.grid(16, 64, 16):
cse_var_3: T.int32 = i0_2 * 1024 + i1 * 16 + i3
A_buf_3[cse_var_3] = A_buf_1[cse_var_3] + A_buf_2[cse_var_3 + 16384]
i0_3 = T.int32()
T.attr(T.iter_var(i0_3, None, "DataPar", ""), "pragma_dma_copy", 1)
for i0_3, i1, i3 in T.grid(16, 64, 16):
cse_var_4: T.int32 = i0_3 * 1024 + i1 * 16 + i3
C_1 = T.Buffer((16384,), "int8", data=C.data)
C_1[cse_var_4] = T.Cast("int8", A_buf_3[cse_var_4])
这就结束了本教程的调度部分。
TVM 计算#
在完成指定调度之后,可以将它编译成 TVM 函数。默认情况下,TVM 编译成可以直接从 python 调用的类型消除(type-erased)函数。
在下面一行中,使用 tvm.build() 来创建函数。build 函数接受调度、函数的期望签名(包括输入和输出)以及想要编译的目标语言。
# ctx = tvm.target.Target("ext_dev", host=env.target_host)
target = "ext_dev"
my_vadd = vta.build(s, [A, B, C], target=target, name="my_vadd")
保存 Module#
TVM 把模块保存到文件中,这样以后就可以加载回来了。这被称为提前编译(ahead-of-time compilation),可以节省一些编译时间。
更重要的是,这允许在开发机器上交叉编译可执行文件,并通过 RPC 将其发送到 Pynq FPGA 板上执行。
将编译后的模块写入 object 文件。
temp = tvm.contrib.utils.tempdir()
my_vadd.save(temp.relpath("vadd.o"))
通过 RPC 发送可执行文件:
remote.upload(temp.relpath("vadd.o"))
载入 Module#
可以从文件系统加载编译后的模块来运行代码。
f = remote.load_module("vadd.o")
2024-04-28 14:34:52.112 INFO load_module /tmp/tmpnkosejgz/vadd.o
运行函数#
编译后的 TVM 函数使用简洁的 C API,可以被任何语言调用。
TVM 用 python 提供了数组 API 来帮助快速测试和原型化。数组 API 是基于 DLPack 标准的。
首先创建远程上下文(用于 Pynq 上的远程执行)。
然后
tvm.nd.array对数据进行相应的格式化。f()运行实际的计算。numpy()将结果数组以可解释的格式复制回来。
获取远程设备的上下文:
ctx = remote.ext_dev(0)
使用 tvm.nd.array() 将输入/输出数组格式化为 DLPack 标准:
from tvm.topi.utils import get_const_tuple
A_nd = tvm.nd.array(A_packed, ctx)
B_nd = tvm.nd.array(B_packed, ctx)
C_nd = tvm.nd.empty(get_const_tuple(C.shape), C.dtype, ctx)
调用模块来执行计算:
f(A_nd, B_nd, C_nd)
验证 Correctness#
使用 numpy 计算引用的结果,并断言矩阵乘法的输出确实是正确的:
A_orig.shape, B_orig.shape
((16, 1024), (16, 1024))
C_ref = (A_orig.astype(env.acc_dtype) + B_orig.astype(env.acc_dtype)).astype(C.dtype)
C_ref = C_ref.reshape(m//env.BATCH, env.BATCH, n//env.BLOCK_OUT, env.BLOCK_OUT).transpose((0, 2, 1, 3))
np.testing.assert_equal(C_ref, C_nd.numpy())
print("ALU 加法测试成功!")
ALU 加法测试成功!
获取 ALU 数据搬运情况#
time_f = f.time_evaluator(f.entry_name, ctx, number=20)
if env.TARGET in ["sim", "tsim"]:
# Check if we're in local RPC mode (allows us to rebuild the
# runtime on the fly when varying the VTA designs)
local_rpc = int(os.environ.get("VTA_LOCAL_SIM_RPC", "0"))
if local_rpc:
if env.TARGET == "sim":
remote.get_function("vta.simulator.profiler_clear")()
else:
remote.get_function("vta.tsim.profiler_clear")()
cost = time_f(A_nd, B_nd, C_nd)
if env.TARGET == "sim":
stats = json.loads(remote.get_function("vta.simulator.profiler_status")())
else:
stats = json.loads(remote.get_function("vta.tsim.profiler_status")())
else:
simulator.clear_stats()
cost = time_f(A_nd, B_nd, C_nd)
stats = simulator.stats()
else:
cost = time_f(A_nd, B_nd, C_nd)
[14:34:52] /media/pc/data/lxw/ai/tvm/src/runtime/profiling.cc:101: Warning: No timer implementation for ext_dev, using default timer instead. It may be inaccurate or have extra overhead.
stats
{'inp_load_nbytes': 0,
'wgt_load_nbytes': 0,
'acc_load_nbytes': 2752512,
'uop_load_nbytes': 84,
'out_store_nbytes': 344064,
'gemm_counter': 0,
'alu_counter': 21504}
cost
BenchmarkResult(min=4.375225e-05, mean=4.375225e-05, median=4.375225e-05, max=4.375225e-05, std=0.0, results=(4.375225e-05,))