快速上手模型#
import torch
import torchvision.models as models
torch.set_float32_matmul_precision('high')
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
from torch._dynamo.optimizations.backends import tvm_compile, tvm_meta_schedule
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(
x_ptr, # *Pointer* to first input vector
y_ptr, # *Pointer* to second input vector
output_ptr, # *Pointer* to output vector
n_elements, # Size of the vector
BLOCK_SIZE: tl.constexpr, # Number of elements each program should process
# NOTE: `constexpr` so it can be used as a shape value
):
# There are multiple 'program's processing different data. We identify which program
# we are here
pid = tl.program_id(axis=0) # We use a 1D launch grid so axis is 0
# This program will process inputs that are offset from the initial data.
# for instance, if you had a vector of length 256 and block_size of 64, the programs
# would each access the elements [0:64, 64:128, 128:192, 192:256].
# Note that offsets is a list of pointers
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# Create a mask to guard memory operations against out-of-bounds accesses
mask = offsets < n_elements
# Load x and y from DRAM, masking out any extra elements in case the input is not a
# multiple of the block size
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
# Write x + y back to DRAM
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
# We need to preallocate the output
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
# The SPMD launch grid denotes the number of kernel instances that run in parallel.
# It is analogous to CUDA launch grids. It can be either Tuple[int], or Callable(metaparameters) -> Tuple[int]
# In this case, we use a 1D grid where the size is the number of blocks
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
# NOTE:
# - each torch.tensor object is implicitly converted into a pointer to its first element.
# - `triton.jit`'ed functions can be index with a launch grid to obtain a callable GPU kernel
# - don't forget to pass meta-parameters as keywords arguments
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
# We return a handle to z but, since `torch.cuda.synchronize()` hasn't been called, the kernel is still
# running asynchronously at this point.
return output
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
output_torch = x + y
output_triton = add(x, y)
print(output_torch)
print(output_triton)
print(
f'The maximum difference between torch and triton is '
f'{torch.max(torch.abs(output_torch - output_triton))}'
)
tensor([1.3713, 1.3076, 0.4940, ..., 0.6724, 1.2141, 0.9733], device='cuda:0')
tensor([1.3713, 1.3076, 0.4940, ..., 0.6724, 1.2141, 0.9733], device='cuda:0')
The maximum difference between torch and triton is 0.0
@triton.testing.perf_report(
triton.testing.Benchmark(
x_names=['size'], # argument names to use as an x-axis for the plot
x_vals=[
2 ** i for i in range(12, 28, 1)
], # different possible values for `x_name`
x_log=True, # x axis is logarithmic
line_arg='provider', # argument name whose value corresponds to a different line in the plot
line_vals=['triton', 'torch'], # possible values for `line_arg`
line_names=['Triton', 'Torch'], # label name for the lines
styles=[('blue', '-'), ('green', '-')], # line styles
ylabel='GB/s', # label name for the y-axis
plot_name='vector-add-performance', # name for the plot. Used also as a file name for saving the plot.
args={}, # values for function arguments not in `x_names` and `y_name`
)
)
def benchmark(size, provider):
x = torch.rand(size, device='cuda', dtype=torch.float32)
y = torch.rand(size, device='cuda', dtype=torch.float32)
if provider == 'torch':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: x + y)
if provider == 'triton':
ms, min_ms, max_ms = triton.testing.do_bench(lambda: add(x, y))
gbps = lambda ms: 12 * size / ms * 1e-6
return gbps(ms), gbps(max_ms), gbps(min_ms)
benchmark.run(print_data=True, show_plots=True)
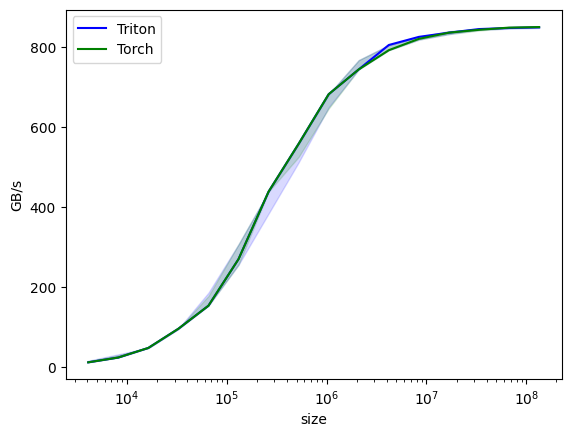
vector-add-performance:
size Triton Torch
0 4096.0 12.000000 12.000000
1 8192.0 24.000000 24.000000
2 16384.0 48.000000 48.000000
3 32768.0 96.000000 96.000000
4 65536.0 153.600004 153.600004
5 131072.0 270.065929 270.065929
6 262144.0 438.857137 438.857137
7 524288.0 558.545450 558.545450
8 1048576.0 682.666643 682.666643
9 2097152.0 744.727267 744.727267
10 4194304.0 805.770507 792.774204
11 8388608.0 826.084057 821.124496
12 16777216.0 836.629789 836.629789
13 33554432.0 845.625825 843.811163
14 67108864.0 848.362445 849.278610
15 134217728.0 849.923938 850.656574