扩展 ONNX 注册表#
参考:扩展 ONNX 注册表
本教程是对 ONNX 注册表的简介,它使用户能够实现新的 ONNX 算子,甚至用新实现替换现有算子。
在模型导出到 ONNX 的过程中,PyTorch 模型被降低到由 ATen 算子组成的中间表示。虽然 ATen 算子由 PyTorch 核心团队维护,但 ONNX 导出器团队负责独立地通过 ONNX Script 将这些算子实现到 ONNX。用户也可以用自己的实现替换 ONNX 导出器团队实现的行为,以修复错误或针对特定的 ONNX 运行时改进性能。
ONNX 注册表管理 PyTorch 算子与 ONNX 算子对应项之间的映射,并提供 API 以扩展注册表。
在本教程中,我们将涵盖三种需要使用自定义操作符扩展 ONNX 注册表的场景:
不受支持的 ATen 算子
具有现有 ONNX 运行时支持的自定义算子
没有 ONNX 运行时支持的自定义算子
不受支持的 ATen 算子#
尽管 ONNX 导出器团队尽力支持所有的 ATen 算子,但其中一些可能尚未得到支持。在这一节中,我们将演示如何将不受支持的 ATen 算子添加到 ONNX 注册表中。
备注
实现不受支持的 ATen 算子的步骤与用自定义实现替换现有 ATen 算子的实现相同。由于我们在这个教程中实际上没有一个不受支持的 ATen 算子符可以使用,我们将利用这个机会,用自定义实现来替换 aten::add.Tensor 的实现,就像如果该算子不存在于 ONNX 注册表中一样。
当模型由于不受支持的操作符而无法导出到 ONNX 时,ONNX 导出器将显示类似于以下的错误消息:
RuntimeErrorWithDiagnostic: Unsupported FX nodes: {'call_function': ['aten.add.Tensor']}.
错误消息指示不受支持的 ATen 算子的完全限定名称是 aten::add.Tensor。算子的完全限定名称由命名空间、算子名称和重载组成,格式为 namespace::operator_name.overload。
要为不受支持的 ATen 算子添加支持或替换现有算子的实现,需要:
ATen 算子的完全限定名称(例如
aten::add.Tensor)。此信息总是如上所示的错误消息中出现。使用 ONNX Script 的算子实现。ONNX Script 是本教程的先决条件。
因为
aten::add.Tensor已经被 ONNX 注册表支持,我们将演示如何用自定义实现替换它,但请记住,同样的步骤适用于支持新的不受支持的 ATen 算子。
这是可能的,因为 OnnxRegistry 允许用户覆盖算子注册。我们将用我们的自定义实现覆盖 aten::add.Tensor 的注册,并验证它的存在。
import torch
import onnxruntime
import onnxscript
from onnxscript import opset18 # opset 18 是目前最新的(也是唯一支持的)版本。
class Model(torch.nn.Module):
def forward(self, input_x, input_y):
return torch.ops.aten.add(input_x, input_y) # generates a aten::add.Tensor node
input_add_x = torch.randn(3, 4)
input_add_y = torch.randn(3, 4)
aten_add_model = Model()
# 现在,我们创建实现 `aten::add.Tensor` 的 ONNX Script 函数。
# 函数名称(例如 `custom_aten_add`)会显示在 ONNX 图中,因此我们建议使用直观的名称。
custom_aten = onnxscript.values.Opset(domain="custom.aten", version=1)
# NOTE:函数签名必须与不受支持的 ATen 算子的签名匹配。
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE:所有属性必须用类型提示进行注解。
@onnxscript.script(custom_aten)
def custom_aten_add(input_x, input_y, alpha: float = 1.0):
alpha = opset18.CastLike(alpha, input_y)
input_y = opset18.Mul(input_y, alpha)
return opset18.Add(input_x, input_y)
# 现在我们已经拥有支持不受支持的 ATen 算子所需的一切。
# 让我们将 `custom_aten_add` 函数注册到 ONNX 注册表,并再次将模型导出到 ONNX。
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="aten", op_name="add", overload="Tensor", function=custom_aten_add
)
print(f"aten::add.Tensor is supported by ONNX registry: \
{onnx_registry.is_registered_op(namespace='aten', op_name='add', overload='Tensor')}"
)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
onnx_program = torch.onnx.dynamo_export(
aten_add_model, input_add_x, input_add_y, export_options=export_options
)
aten::add.Tensor is supported by ONNX registry: True
/media/pc/data/tmp/cache/conda/envs/py311/lib/python3.11/site-packages/torch/onnx/_internal/exporter.py:137: UserWarning: torch.onnx.dynamo_export only implements opset version 18 for now. If you need to use a different opset version, please register them with register_custom_op.
warnings.warn(
/media/pc/data/tmp/cache/conda/envs/py311/lib/python3.11/site-packages/torch/onnx/_internal/exporter.py:137: UserWarning: torch.onnx.dynamo_export only implements opset version 18 for now. If you need to use a different opset version, please register them with register_custom_op.
warnings.warn(
现在让我们检查模型,并验证模型是否使用了 custom_aten_add 而不是 aten::add.Tensor。图中有一个用于 custom_aten_add 的图节点,在其内部有四个函数节点,分别对应每个算子,以及一个用于常量属性的节点。
# graph node domain is the custom domain we registered
assert onnx_program.model_proto.graph.node[0].domain == "custom.aten"
assert len(onnx_program.model_proto.graph.node) == 1
# graph node name is the function name
assert onnx_program.model_proto.graph.node[0].op_type == "custom_aten_add"
# function node domain is empty because we use standard ONNX operators
assert onnx_program.model_proto.functions[0].node[3].domain == ""
# function node name is the standard ONNX operator name
assert onnx_program.model_proto.functions[0].node[3].op_type == "Add"
这就是 custom_aten_add_model 在 ONNX 图中使用 Netron 的样子:

在 custom_aten_add 函数内部,我们可以看到在函数中使用的三个 ONNX 节点(CastLike、Add 和 Mul),以及常量属性: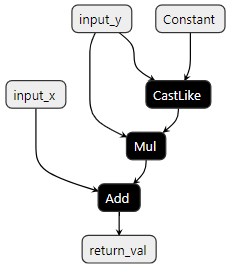
这就是我们需要做的全部工作,以将新的 ATen 算子注册到 ONNX 注册表中。作为额外的一步,我们可以使用 ONNX Runtime 运行模型,并将结果与 PyTorch 进行比较。
# Use ONNX Runtime to run the model, and compare the results with PyTorch
onnx_program.save("./custom_add_model.onnx")
ort_session = onnxruntime.InferenceSession(
"./custom_add_model.onnx", providers=['CPUExecutionProvider']
)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_add_x, input_add_y)
onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
torch_outputs = aten_add_model(input_add_x, input_add_y)
torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs)
assert len(torch_outputs) == len(onnxruntime_outputs)
for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs):
torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))
具有现有 ONNX Runtime 支持的自定义算子#
在这种情况下,用户使用标准的 PyTorch 算子创建模型,但 ONNX 运行时(例如 Microsoft 的 ONNX Runtime)可以为该内核提供自定义实现,有效地替换 ONNX 注册表中的现有实现。另一个用例是,当用户想要使用现有 ONNX 算子的自定义实现来修复错误或提高特定算子的性能时。为了实现这一点,我们只需要将新实现注册到现有的 ATen 完全限定名称。
在以下示例中,我们使用了来自 ONNX Runtime 的 com.microsoft.Gelu,它与 ONNX 规范中的 Gelu 不同。因此,我们用命名空间 com.microsoft 和算子名称 Gelu 注册了 Gelu。
在我们开始之前,让我们检查 aten::gelu.default 是否真的受到 ONNX 注册表的支持。
onnx_registry = torch.onnx.OnnxRegistry()
print(f"aten::gelu.default is supported by ONNX registry: \
{onnx_registry.is_registered_op(namespace='aten', op_name='gelu', overload='default')}")
aten::gelu.default is supported by ONNX registry: True
/media/pc/data/tmp/cache/conda/envs/py311/lib/python3.11/site-packages/torch/onnx/_internal/exporter.py:137: UserWarning: torch.onnx.dynamo_export only implements opset version 18 for now. If you need to use a different opset version, please register them with register_custom_op.
warnings.warn(
在我们的示例中,aten::gelu.default 算子受到 ONNX 注册表的支持,所以 onnx_registry.is_registered_op() 返回 True。
class CustomGelu(torch.nn.Module):
def forward(self, input_x):
return torch.ops.aten.gelu(input_x)
# com.microsoft is an official ONNX Runtime namspace
custom_ort = onnxscript.values.Opset(domain="com.microsoft", version=1)
# NOTE: The function signature must match the signature of the unsupported ATen operator.
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE: All attributes must be annotated with type hints.
@onnxscript.script(custom_ort)
def custom_aten_gelu(input_x, approximate: str = "none"):
# We know com.microsoft::Gelu is supported by ONNX Runtime
# It's only not supported by ONNX
return custom_ort.Gelu(input_x)
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="aten", op_name="gelu", overload="default", function=custom_aten_gelu)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
aten_gelu_model = CustomGelu()
input_gelu_x = torch.randn(3, 3)
onnx_program = torch.onnx.dynamo_export(
aten_gelu_model, input_gelu_x, export_options=export_options
)
'Gelu' is not a known op in 'com.microsoft'
让我们检查模型,并验证模型是否使用了 custom_aten_gelu() 而不是 aten::gelu。注意图中有一个用于 custom_aten_gelu 的图节点,在 custom_aten_gelu 内部,有一个命名空间为 com.microsoft 的 Gelu 函数节点。
# graph node domain is the custom domain we registered
assert onnx_program.model_proto.graph.node[0].domain == "com.microsoft"
# graph node name is the function name
assert onnx_program.model_proto.graph.node[0].op_type == "custom_aten_gelu"
# function node domain is the custom domain we registered
assert onnx_program.model_proto.functions[0].node[0].domain == "com.microsoft"
# function node name is the node name used in the function
assert onnx_program.model_proto.functions[0].node[0].op_type == "Gelu"
下面的图表显示了使用 Netron 的 custom_aten_gelu_model ONNX 图: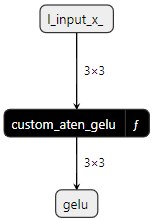
在 custom_aten_gelu 函数内部,我们可以看到在函数中使用的来自模块 com.microsoft 的 Gelu 节点: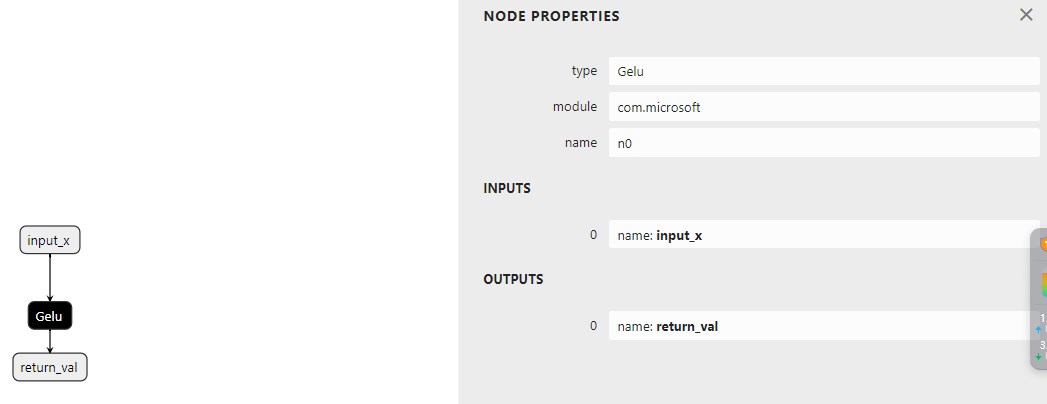 。
。
这就是我们需要做的全部工作。作为额外的步骤,我们可以使用 ONNX Runtime 运行模型,并将结果与 PyTorch 进行比较。
onnx_program.save("./custom_gelu_model.onnx")
ort_session = onnxruntime.InferenceSession(
"./custom_gelu_model.onnx", providers=['CPUExecutionProvider']
)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_gelu_x)
onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)}
onnxruntime_outputs = ort_session.run(None, onnxruntime_input)
torch_outputs = aten_gelu_model(input_gelu_x)
torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs)
assert len(torch_outputs) == len(onnxruntime_outputs)
for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs):
torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))
没有 ONNX Runtime 支持的自定义算子#
在这种情况下,算子不受任何 ONNX 运行时的支持,但我们希望将其作为自定义算子使用在 ONNX 图中。因此,我们需要在三个地方实现该算子:
PyTorch FX 图
ONNX 注册表
ONNX 运行时
在以下示例中,我们希望使用一个自定义算子,它接受一个张量输入,并返回一个输出。该算子将输入加到自身,并返回四舍五入的结果。
在 PyTorch FX 图中注册自定义算子(Beta)#
首先,我们需要在 PyTorch FX 图中实现该算子。这可以通过使用 torch._custom_op 来完成。
# NOTE: This is a beta feature in PyTorch, and is subject to change.
from torch._custom_op import impl as custom_op
@custom_op.custom_op("mylibrary::addandround_op")
def addandround_op(tensor_x: torch.Tensor) -> torch.Tensor:
...
@addandround_op.impl_abstract()
def addandround_op_impl_abstract(tensor_x):
return torch.empty_like(tensor_x)
@addandround_op.impl("cpu")
def addandround_op_impl(tensor_x):
return torch.round(tensor_x + tensor_x) # add x to itself, and round the result
torch._dynamo.allow_in_graph(addandround_op)
class CustomFoo(torch.nn.Module):
def forward(self, tensor_x):
return addandround_op(tensor_x)
input_addandround_x = torch.randn(3)
custom_addandround_model = CustomFoo()
在 ONNX 注册表中注册自定义算子#
对于步骤2和3,我们需要在 ONNX 注册表中实现该算子。在这个例子中,我们将使用命名空间 test.customop 和算子名称 CustomOpOne 以及 CustomOpTwo 在 ONNX 注册表中实现该算子。这两个算子已在 cpu_ops.cc 中注册并构建。
custom_opset = onnxscript.values.Opset(domain="test.customop", version=1)
# NOTE: The function signature must match the signature of the unsupported ATen operator.
# https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml
# NOTE: All attributes must be annotated with type hints.
@onnxscript.script(custom_opset)
def custom_addandround(input_x):
# The same as opset18.Add(x, x)
add_x = custom_opset.CustomOpOne(input_x, input_x)
# The same as opset18.Round(x, x)
round_x = custom_opset.CustomOpTwo(add_x)
# Cast to FLOAT to match the ONNX type
return opset18.Cast(round_x, to=1)
onnx_registry = torch.onnx.OnnxRegistry()
onnx_registry.register_op(
namespace="mylibrary", op_name="addandround_op", overload="default", function=custom_addandround
)
export_options = torch.onnx.ExportOptions(onnx_registry=onnx_registry)
onnx_program = torch.onnx.dynamo_export(
custom_addandround_model, input_addandround_x, export_options=export_options
)
onnx_program.save("./custom_addandround_model.onnx")
'CustomOpOne' is not a known op in 'test.customop'
'CustomOpTwo' is not a known op in 'test.customop'
/media/pc/data/tmp/cache/conda/envs/py311/lib/python3.11/site-packages/torch/onnx/_internal/exporter.py:137: UserWarning: torch.onnx.dynamo_export only implements opset version 18 for now. If you need to use a different opset version, please register them with register_custom_op.
warnings.warn(
onnx_program 通过 onnx_program.model_proto 将导出的模型暴露为 protobuf。图中有一个用于 custom_addandround 的图节点,在 custom_addandround 内部,有两个函数节点,每个算子一个。
assert onnx_program.model_proto.graph.node[0].domain == "test.customop"
assert onnx_program.model_proto.graph.node[0].op_type == "custom_addandround"
assert onnx_program.model_proto.functions[0].node[0].domain == "test.customop"
assert onnx_program.model_proto.functions[0].node[0].op_type == "CustomOpOne"
assert onnx_program.model_proto.functions[0].node[1].domain == "test.customop"
assert onnx_program.model_proto.functions[0].node[1].op_type == "CustomOpTwo"
在 ONNX Runtime 中注册自定义算子#
要将您的自定义算子库链接到 ONNX Runtime,您需要将 C++ 代码编译成共享库,并将其链接到 ONNX Runtime。请按照以下说明操作:
按照 ONNX Runtime 的指令用 C++ 实现您的自定义算子。
从 ONNX Runtime 发布页面下载 ONNX Runtime 源码分发版。
编译并将您的自定义算子库链接到 ONNX Runtime,例如:
$ gcc -shared -o libcustom_op_library.so custom_op_library.cc -L /path/to/downloaded/ort/lib/ -lonnxruntime -fPIC
使用 ONNX Runtime Python API 运行模型,并将结果与 PyTorch 进行比较。
ort_session_options = onnxruntime.SessionOptions() # NOTE: Link the custom op library to ONNX Runtime and replace the path # with the path to your custom op library ort_session_options.register_custom_ops_library( "/path/to/libcustom_op_library.so" ) ort_session = onnxruntime.InferenceSession( "./custom_addandround_model.onnx", providers=['CPUExecutionProvider'], sess_options=ort_session_options) def to_numpy(tensor): return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() onnx_input = onnx_program.adapt_torch_inputs_to_onnx(input_addandround_x) onnxruntime_input = {k.name: to_numpy(v) for k, v in zip(ort_session.get_inputs(), onnx_input)} onnxruntime_outputs = ort_session.run(None, onnxruntime_input) torch_outputs = custom_addandround_model(input_addandround_x) torch_outputs = onnx_program.adapt_torch_outputs_to_onnx(torch_outputs) assert len(torch_outputs) == len(onnxruntime_outputs) for torch_output, onnxruntime_output in zip(torch_outputs, onnxruntime_outputs): torch.testing.assert_close(torch_output, torch.tensor(onnxruntime_output))