Strawberry 简介#
参考:Strawberry
安装:
pip install 'strawberry-graphql[debug-server]'
定义模式#
每个 GraphQL 服务器都使用 模式 (schema)来定义客户端可以查询的数据结构。在本例中,将创建服务器,用于按标题和作者查询图书集合。
在你最喜欢的编辑器中创建名为 schema.py 的文件,包含以下内容:
import strawberry
@strawberry.type
class Book:
title: str
author: str
@strawberry.type
class Query:
books: list[Book]
这将创建 GraphQL 模式,其中客户端将能够执行名为 books 的查询,该查询将返回包含零本或多本图书的列表。
定义数据集#
有了模式的结构,可以定义数据本身了。Strawberry 可以使用任何数据源(例如数据库、REST API、文件等)。在本教程中,将使用硬编码数据。
创建返回一些书的函数。
def get_books():
return [
Book(
title="The Great Gatsby",
author="F. Scott Fitzgerald",
),
]
因为 strawberry 使用 python 类来创建模式,这意味着也可以重用它们来创建数据对象。
定义解析器#
有返回一些书籍的函数,但是 Strawberry 不知道在执行查询时应该使用它。为了解决这个问题,需要更新我们的查询来为图书指定解析器(resolver)。解析器告诉 Strawberry 如何获取与特定字段相关的数据。
更新我们的查询:
@strawberry.type
class Query:
books: list[Book] = strawberry.field(resolver=get_books)
使用 strawberry.field 允许为特定的字段指定解析器。
备注
不需要为 Book 的字段指定任何解析器,这是因为 Strawberry 为每个字段添加了默认值,返回该字段的值。
创建模式并运行它#
已经定义了数据和查询,现在需要做的是创建 GraphQL 模式并启动服务器。要创建模式,添加以下代码:
schema = strawberry.Schema(query=Query)
执行如下命令:
strawberry server schema
这将启动调试服务器,你应该看到以下输出:
Running strawberry on http://0.0.0.0:8000/graphql 🍓
执行第一个查询#
现在可以执行 GraphQL 查询了。Strawberry 附带了名为 GraphiQL 的工具。打开它,请访问 http://0.0.0.0:8000/graphql,你应该会看到这样的东西:
GraphiQL UI 包括:
用于编写查询的文本区域(左侧)
用于执行查询的 Play 按钮(中间的三角形按钮)
用于查看查询结果的文本区域(右侧)
用于检查模式和生成文档的视图(通过右侧的选项卡)
服务器支持名为 books 的查询。让我们执行它!将以下字符串粘贴到左侧区域,然后单击播放按钮:
{
books {
title
author
}
}
应该看到硬编码的数据出现在右边:
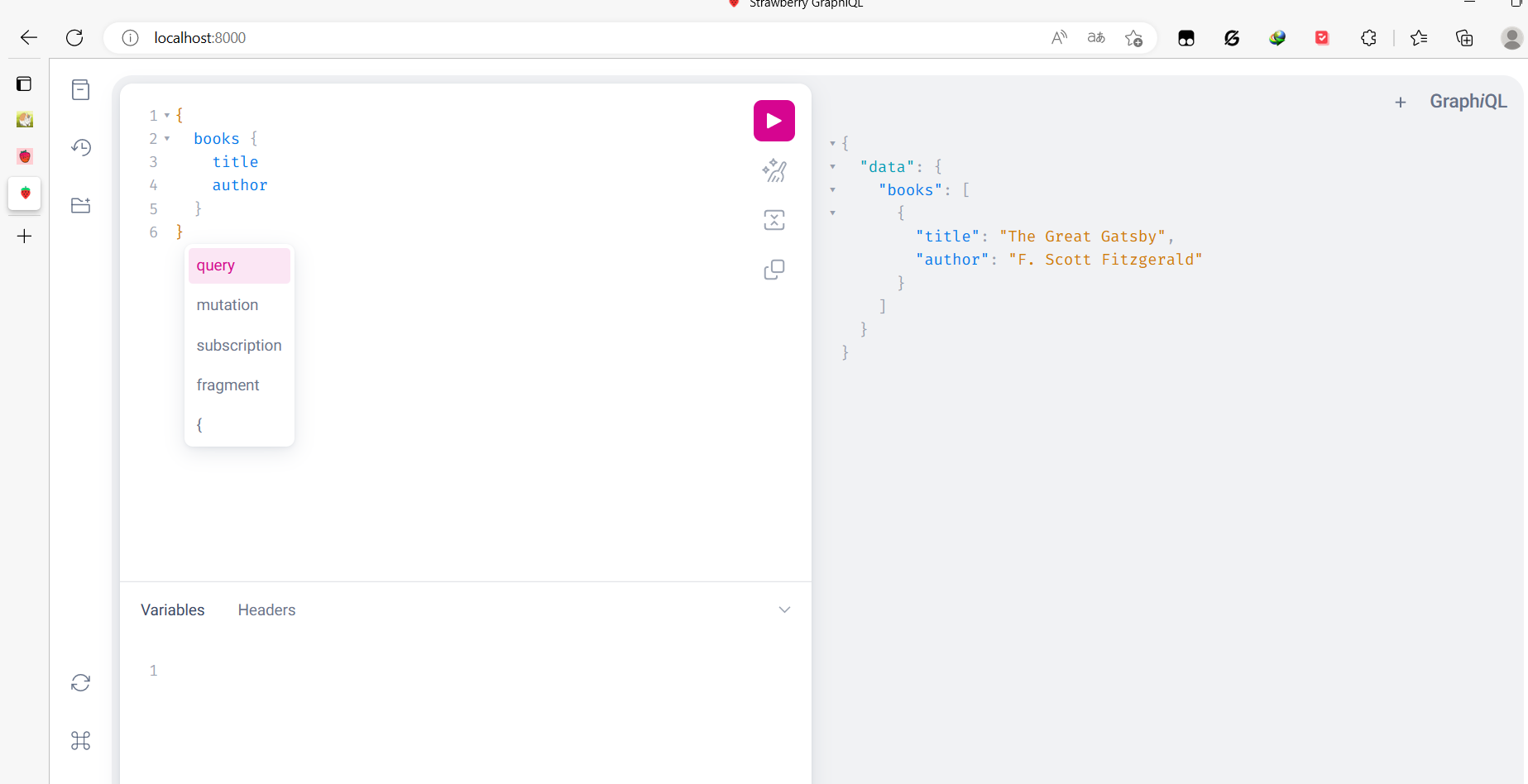
GraphQL 允许客户端只查询需要的字段,然后从查询中删除 author 并再次运行它。响应现在应该只显示每本书的标题。