Python 提供了通用网关接口(Common Gateway Interface,CGI)脚本的支持模块 cgi。HTTP 服务器调用 CGI 脚本,通常用于处理通过 HTML <FORM> 或 <ISINDEX> 元素提交的用户输入。
通常,CGI 脚本位于服务器的特殊 cgi-bin 目录中。HTTP 服务器将有关请求的各种信息(例如客户端的主机名,请求的 URL,查询字符串以及许多其他东西)放置在脚本的 Shell 环境中,执行脚本,并将脚本的输出发送回给客户端。CGI 程序可以是 Python 脚本,PERL 脚本,SHELL 脚本,C 或者 C++ 程序等,本文仅仅考虑 Python。
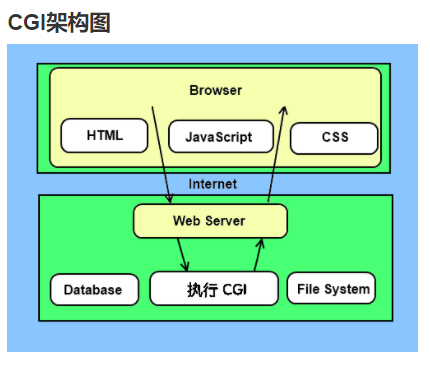
脚本的输入也连接到客户端,有时以这种方式读取表单数据。在其他时候,表单数据是通过 URL 的“查询字符串”部分传递的。该模块旨在处理不同的情况,并为 Python 脚本提供更简单的界面。它还提供了许多实用程序,可帮助调试脚本,并且最新添加的功能是支持从表单上传文件(如果您的浏览器支持的话)。
CGI 脚本的输出应由两部分组成,并用空白行分隔。第一部分包含许多 headers,告诉客户端要遵循的数据类型。生成最小 header 部分的 Python 代码如下所示:
print("Content-Type: text/html") # HTML is following
print() # blank line, end of headers第二部分通常是 HTML,它允许客户端软件显示带有 header,嵌入式图像等格式良好的文本。这是 Python 代码,可打印简单的 HTML:
print("<TITLE>CGI script output</TITLE>")
print("<H1>This is my first CGI script</H1>")
print("Hello, world!")Python 中 CGI 模块中文乱码的问题解决方案:去除 print(<meta charset="UTF-8">) 这句即可。
cgitb —— 用于 CGI 脚本的回溯管理器
cgitb 模块提供了用于 Python 脚本的特殊异常处理程序。(这个名称有一点误导性。它最初是设计用来显示 HTML 格式的 CGI 脚本详细回溯信息。但后来被一般化为也可显示纯文本格式的回溯信息。) 激活这个模块之后,如果发生了未被捕获的异常,将会显示详细的已格式化的报告。报告显示内容包括每个层级的源代码摘录,还有当前正在运行的函数的参数和局部变量值,以帮助你调试问题。你也可以选择将此信息保存至文件而不是将其发送至浏览器。
要启用此特性,只需简单地将此代码添加到你的 CGI 脚本的最顶端:
import cgitb
cgitb.enable()enable() 函数的选项可以控制是将报告显示在浏览器中,还是将报告记录到文件供以后进行分析。
cgitb.enable(display=1, logdir=None, context=5, format='html')函数可通过设置sys.excepthook的值以使cgitb模块接管解释器默认的异常处理机制。- 可选参数
display默认为 1 并可被设为 0 来停止将回溯发送至浏览器。如果给出了参数logdir,则回溯会被写入文件。logdir的值应当是一个用于存放所写入文件的目录。可选参数context是要在回溯中的当前源代码行前后显示的上下文行数;默认为 5。如果可选参数format为"html",输出将为 HTML 格式。任何其它值都会强制启用纯文本输出。默认取值为"html"。
- 可选参数
cgitb.text(info, context=5)函数用于处理info(一个包含sys.exc_info()返回结果的 3 元组) 所描述的异常,将其回溯格式化为文本并将结果作为字符串返回。- 可选参数
context是要在回溯中的当前源码行前后显示的上下文行数;默认为 5。
- 可选参数
cgitb.html(info, context=5)函数用于处理info(一个包含sys.exc_info()返回结果的 3 元组) 所描述的异常,将其回溯格式化为 HTML 并将结果作为字符串返回。- 可选参数
context是要在回溯中的当前源码行前后显示的上下文行数;默认为 5。
- 可选参数
cgitb.handler(info=None)函数使用默认设置处理异常(即在浏览器中显示报告,但不记录到文件)。当你捕获了一个异常并希望使用cgitb来报告它时可以使用此函数。可选的info参数应为一个包含异常类型,异常值和回溯对象的 3 元组,与sys.exc_info()所返回的元组完全一致。如果未提供info参数,则会从sys.exc_info()获取当前异常。
在脚本开发过程中使用此功能非常有帮助。cgitb 生成的报告提供的信息可以为您节省大量的时间来查找错误。测试脚本并确信其正常工作后,您随时可以在以后删除 cgitb 行。
FieldStorage
要获取提交的表单数据,请使用 FieldStorage 类。如果表单包含非 ASCII 字符,请使用 encoding 关键字参数设置为为文档定义的编码值。它通常包含在 HTML 文档的 HEAD 部分的 META 标记中或 Content-Type 标头中。这将从标准输入或环境中读取表单内容(取决于根据 CGI 标准设置的各种环境变量的值)。由于它可能消耗标准输入,因此只能实例化一次。
可以像 Python 字典一样为 FieldStorage 实例建立索引。它允许使用 in 运算符进行成员资格测试,并且还支持标准词典方法 keys() 和内置函数 len()。包含空字符串的表单字段将被忽略,并且不会出现在字典中;要保留这些值,请在创建 FieldStorage 实例时为可选的 keep_blank_values 关键字参数提供一个真值。
例如,以下代码(假定已经打印了 Content-Type 标头和空白行)检查字段 name 和 addr 都设置为非空字符串:
form = cgi.FieldStorage()
if "name" not in form or "addr" not in form:
print("<H1>Error</H1>")
print("Please fill in the name and addr fields.")
return
print("<p>name:", form["name"].value)
print("<p>addr:", form["addr"].value)
...further form processing here...在这里,通过 form[key] 访问的字段本身就是 FieldStorage(或 MiniFieldStorage,取决于 form 编码)的实例。实例的 value 属性产生字段的字符串值。getvalue() 方法直接返回此字符串值。它也接受可选的第二个参数作为默认值,如果请求的键不存在,则返回默认值。
如果提交的表单数据包含多个同名字段,则由 form[key] 检索的对象不是 FieldStorage 或 MiniFieldStorage 实例,而是此类实例的列表。同样,在这种情况下,form.getvalue(key) 将返回字符串列表。如果您预计会发生这种情况(当您的 HTML 表单包含多个具有相同名称的字段时),请使用 getlist() 方法,该方法始终返回值列表(这样就无需对单个项目的大小写进行特殊处理)。例如,此代码连接任意数量的用户名字段,并用逗号分隔:
value = form.getlist("username")
usernames = ",".join(value)如果字段表示上传的文件,则通过 value 属性或 getvalue() 方法访问该值将读取内存中的整个文件(以字节为单位)。这可能不是您想要的。您可以通过测试文件名属性或文件属性来测试上传的文件。然后,您可以从 file 属性读取数据,然后将其自动关闭,作为 FieldStorage 实例的垃圾回收的一部分(read() 和 readline() 方法将返回字节):
fileitem = form["userfile"]
if fileitem.file:
# It's an uploaded file; count lines
linecount = 0
while True:
line = fileitem.file.readline()
if not line: break
linecount = linecount + 1FieldStorage 对象还支持在 with 语句中使用,这将在完成后自动关闭它们。
如果在获取上载文件的内容时遇到错误(例如,当用户通过单击“上一步”或“取消”来中断表单提交时),则该字段的对象的完成属性将设置为值 -1。
文件上传草案标准具有从一个字段上传多个文件的可能性(使用递归 multipart/* 编码)。发生这种情况时,该项目将是类似于字典的 FieldStorage 项目。这可以通过测试其 type 属性来确定,该属性应该是 multipart/form-data(或者可能是另一个匹配 multipart/* 的 MIME 类型)。在这种情况下,可以像顶级表单对象一样递归地对其进行迭代。
当表单以“旧”格式(作为查询字符串或作为 application/x-www-form-urlencoded 类型的单个数据部分)提交时,这些项实际上将是 MiniFieldStorage 类的实例。在这种情况下,列表,文件和文件名属性始终为 None。
通过 POST 提交的还具有查询字符串的表单将同时包含 FieldStorage 和 MiniFieldStorage 项。
开始编写 CGI 程序
- 创建文件夹
www/cgi-bin - 编写
www/cgi-bin/hello.py:
print("Content-Type: text/html") # 发送到浏览器并告知浏览器显示的内容类型为"text/html"
print () # 空行,告诉服务器结束头部
print('<html lang="zh-CN">')
print('<head>')
print('<title>Hello Word - 我的第一个 CGI 程序!</title>')
print('</head>')
print('<body>')
print('<h2>Hello Word! 我是第一个 CGI 程序</h2>')
print('</body>')
print('</html>')- 进入目录
www/,并运行 CMD:
$ python -m http.server --cgi 8001- 在浏览器输入 URL:http://localhost:8001/cgi-bin/hello.py,显示效果:
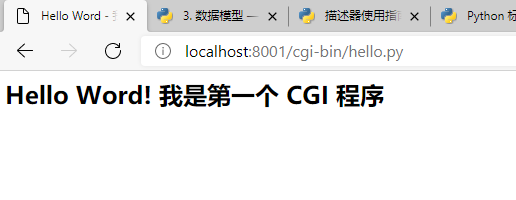
GET 和 POST 方法
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。
使用 GET 方法传输数据
GET 方法发送编码后的用户信息到服务端,数据信息包含在请求页面的 URL上,以”?“号分割, 如下所示:
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2有关 GET 请求的其他一些信息:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
简单的 URL 实例:GET 方法
以下是一个简单的 URL,使用 GET 方法向 hello_get.py 程序发送两个参数:
http://localhost:8001/cgi-bin/hello_get.py?name=上善若水&url=https://xinetzone.github.io/dao/以下为 hello_get.py 的代码:
import cgi
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print("Content-type:text/html")
print()
print("<html>")
print("<head>")
print("<title>CGI 测试实例</title>")
print("</head>")
print("<body>")
print(f"<h2>{site_name} 官网:{site_url}</h2>")
print("</body>")
print("</html>")浏览器请求输出结果:
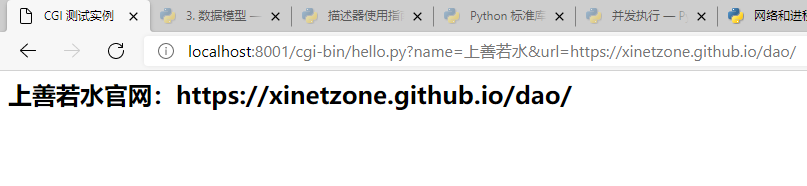
简单的表单实例:GET 方法
以下是一个通过 HTML 的表单使用 GET 方法向服务器发送两个数据,提交的服务器脚本是hello_get.py 文件,hello-get.html 代码如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>上善若水教程</title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="get">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>默认情况下 cgi-bin 目录只能存放脚本文件,我们将 hello_get.html 存储在 test 目录下。
浏览器显示:
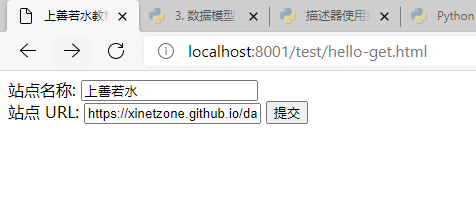
点击提交按钮将会自动跳转到 http://localhost:8001/cgi-bin/hello_get.py?name=上善若水&url=https://xinetzone.github.io/dao/
使用 POST 方法传递数据
使用 POST 方法向服务器传递数据是更安全可靠的,像一些敏感信息如用户密码等需要使用 POST 传输数据。
以下同样是 hello_get.py ,它也可以处理浏览器提交的 POST 表单数据,以下为表单通过 POST 方法(method="post")向服务器脚本 hello_get.py 提交数据:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>上善若水教程</title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="post">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>通过 CGI 程序传递 checkbox 数据
checkbox 用于提交一个或者多个选项数据,HTML 代码如下:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>上善若水教程</title>
</head>
<body>
<form action="/cgi-bin/checkbox.py" method="POST" target="_blank">
<input type="checkbox" name="xinetzone" value="on" /> 上善若水
<input type="checkbox" name="baidu" value="on" /> 百度
<input type="submit" value="选择站点" />
</form>
</body>
</html>以下为 checkbox.py 文件的代码:
import cgi
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('baidu'):
baidu_flag = "是"
else:
baidu_flag = "否"
if form.getvalue('xinetzone'):
xinetzone_flag = "是"
else:
xinetzone_flag = "否"
print("Content-type:text/html")
print()
print("<html>")
print("<head>")
print("<title>CGI 测试实例</title>")
print("</head>")
print("<body>")
print("<h2>上善若水 是否选择了 : %s</h2>" % xinetzone_flag)
print("<h2> 百度 是否选择了 : %s</h2>" % baidu_flag)
print("</body>")
print("</html>")更多参考:Python CGI编程|cgi



